1. NLP发展历程与模型架构
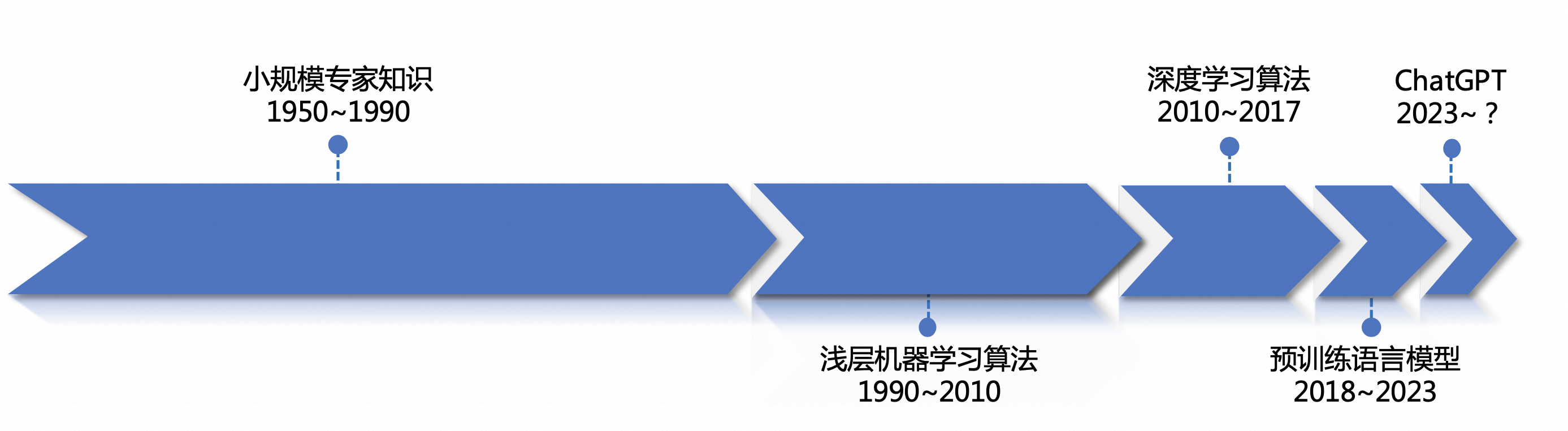
NLP的发展渐趋于统一化:在深度学习时代到来之前,NLP任务高度依赖于手工设计的复杂特征。随后,深度学习的出现极大地减轻了这种特征工程的负担。以BERT和GPT-1为代表的预训练和微调范式,标志着手工特征设计时代的终结。大模型的出现宣告了NLP中间任务的消亡,所有任务都可以统一到语言模型的范畴中。
1.1. 规则阶段(1956~1992)
1.1.1. 阶段特点
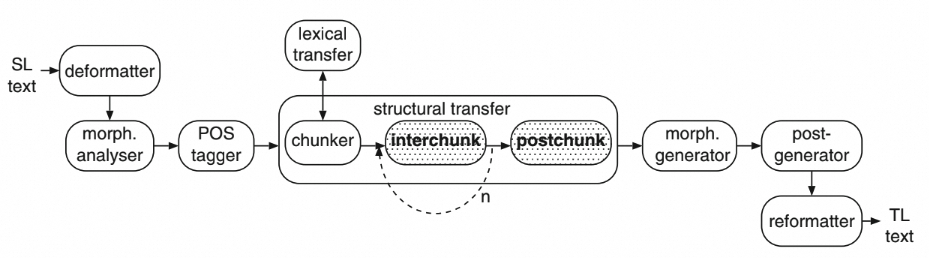
基于规则的机器翻译系统是在内部把各种功能的模块串到一起,由人先从数据中获取知识,归纳出规则,写出来教给机器,然后机器来执行这套规则,从而完成特定任务。
1.1.2. 模型架构
经验规则+系统设计
1.2. 统计机器学习阶段(1993~2012)
1.2.1. 阶段特点
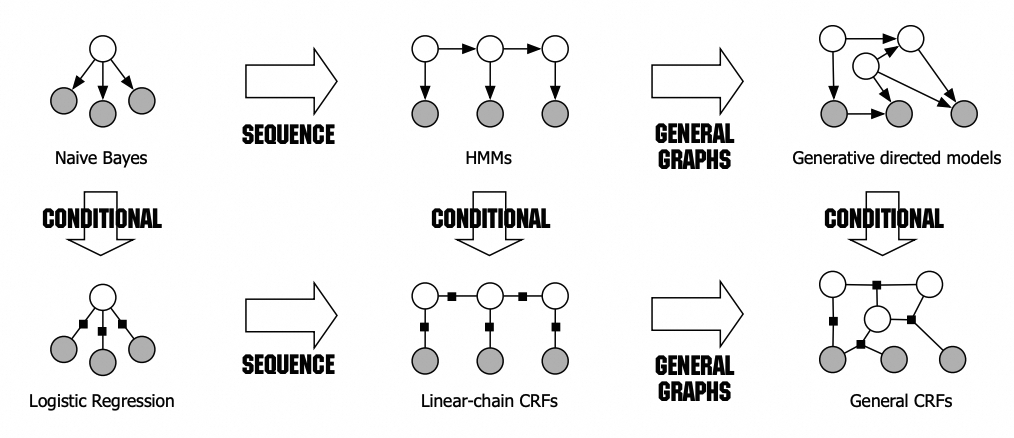
机器翻译系统可拆成语言模型和翻译模型。该阶段相比上一阶段突变性较高,由人转述知识变成机器自动从数据中学习知识,主流技术包括SVM、HMM、MaxEnt、CRF、LM等,当时人工标注数据量在百万级左右。
语言模型(LM)是根据句子一部分来预测下一个词。语言模型训练采用交叉熵Loss,评估采用困惑度(Perplexity,PPL),困惑度越小说明模型准确预测下一个词的把握越大:

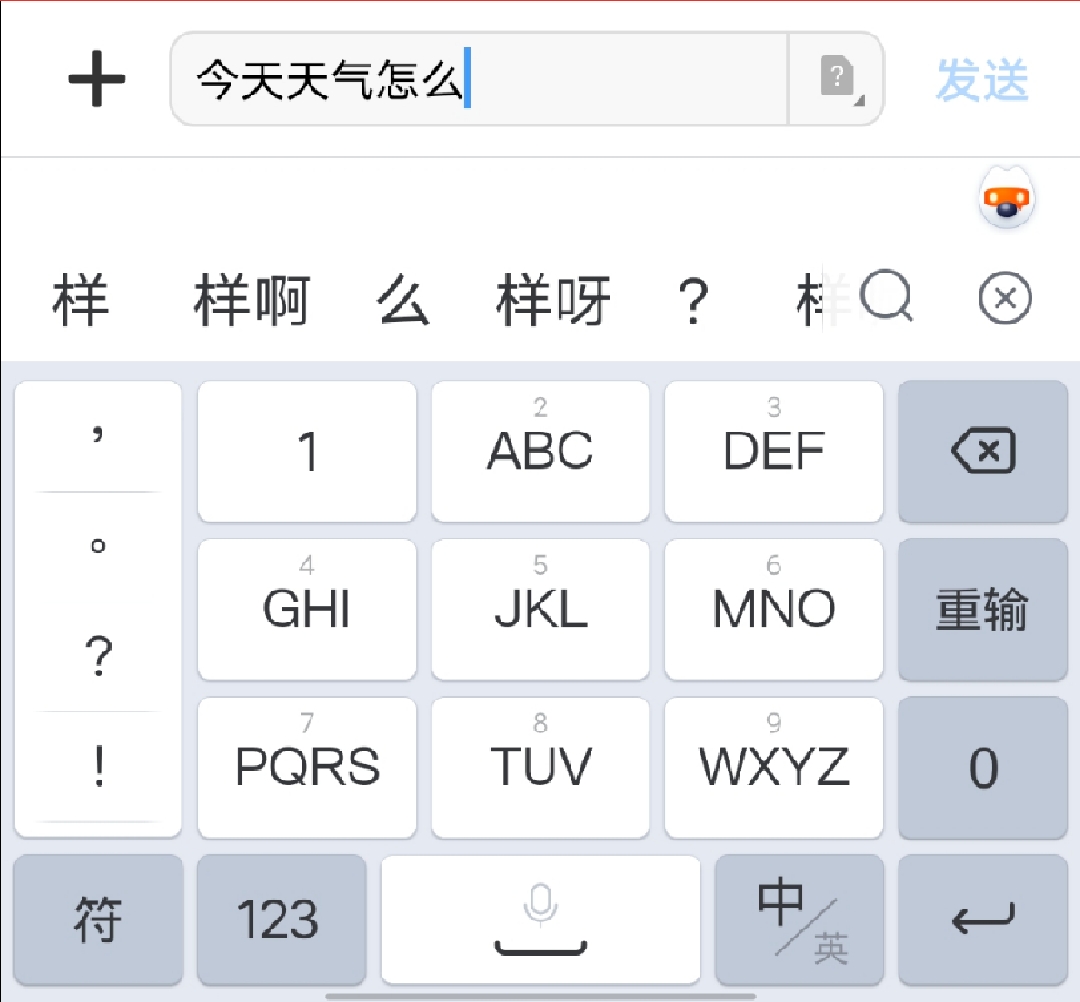
语言模型比较常见的应用是输入法提示:
而大语言模型(LLM)最显著的特点就是训练数据量大、模型参数量大。大多数知识都能用自然语言来描述,互联网文本量大且蕴含大量知识,因此用语言模型来学习知识是个自然而又天才的想法。
1.2.2. 模型架构
浅层模型:
1.3. 深度学习阶段(2013~2018)
1.3.1. 阶段特点
相对上一阶段突变性较低,从离散匹配发展到embedding连续匹配,模型变得更大。该阶段典型技术栈包括Encoder-Decoder、LSTM、Attention、Embedding等,标注数据量提升到千万级。该阶段特点是以神经网络来做表征,下图是经典的词表征学习word2vec结构:
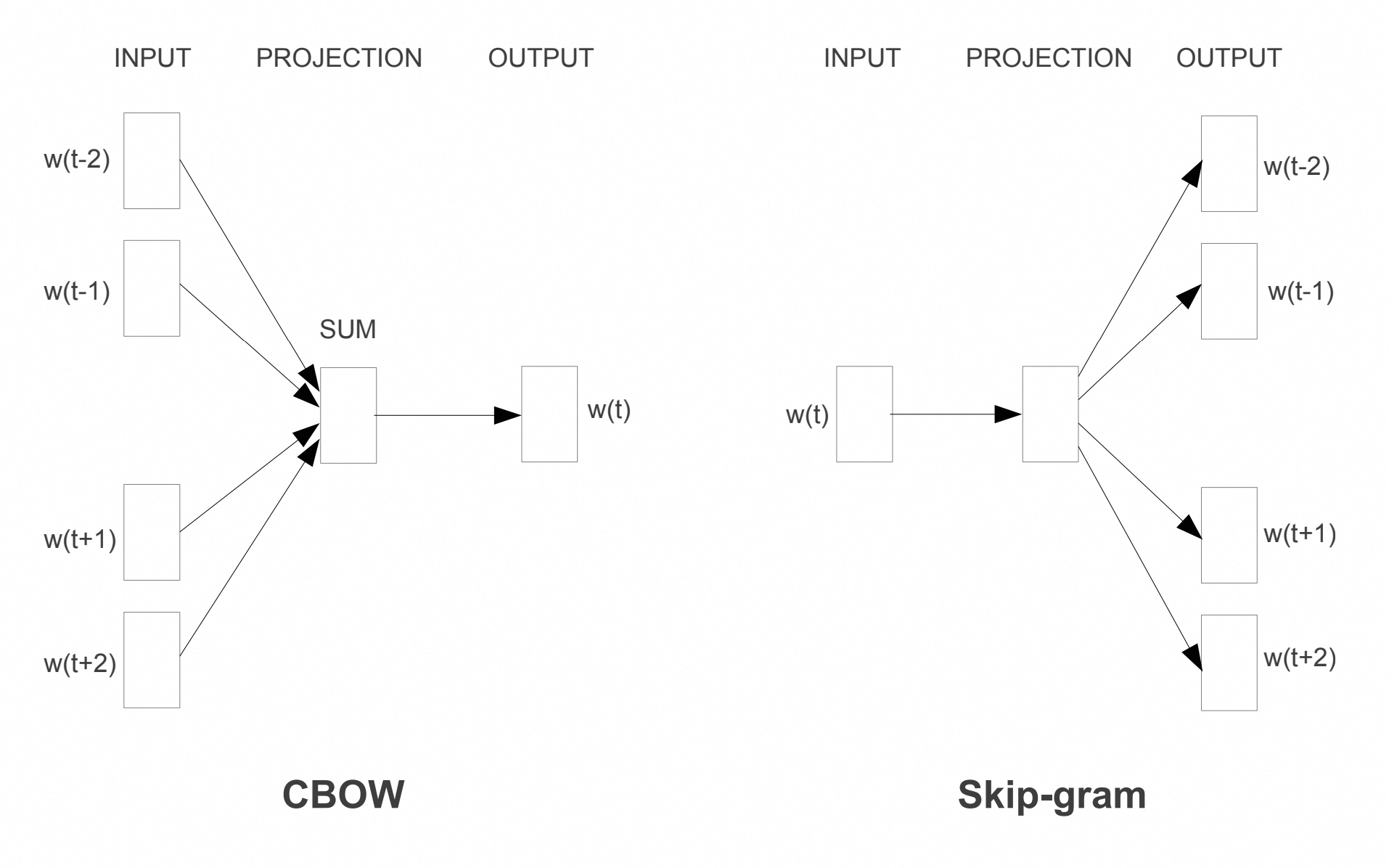
1.3.2. 模型架构
该阶段模型架构主要为了解决具体NLP任务。NLP任务分为自然语言理解(NLU)和自然语言生成(NLG)两大类。
NLU任务一般是对语言基础信息的理解,比如命名实体识别、句法分析、分词、语义角色标注等任务。不同任务会有不同的结构,例如利用stack LSTM解决依存句法分析任务:
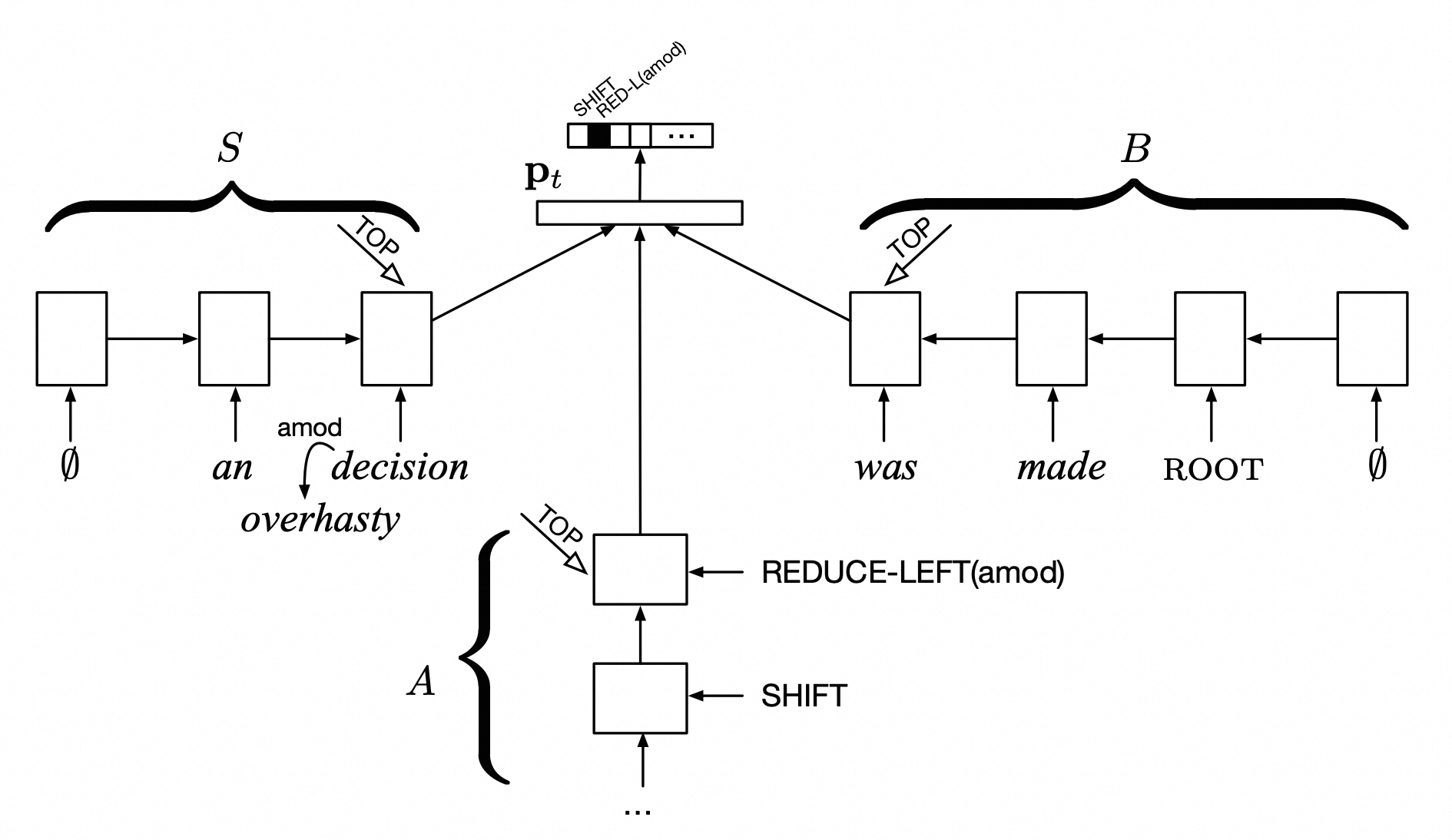
NLG任务一般是语言生成任务,比如生成式摘要,对话生成等任务。基础架构一般是encoder-decoder,例如较早结合encoder-decoder+attention解决机器翻译的工作:
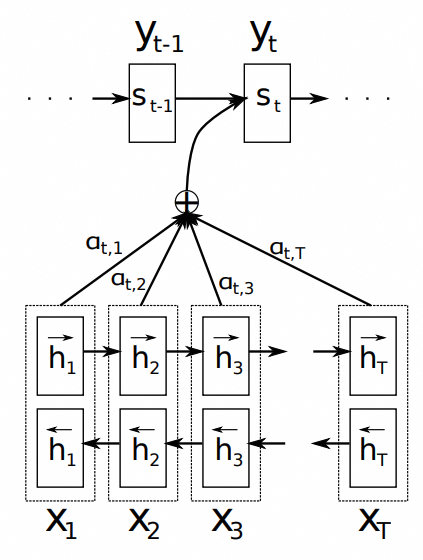
这一阶段,NLP的重心是为每个任务设计合适的模型结构提高任务指标。
1.4. 预训练阶段(2018~2022)
1.4.1. 阶段特点
相比之前的最大变化是加入自监督学习。该阶段系统可分为预训练和微调两个阶段,将预训练数据量扩大3到5倍,典型技术栈包括Encoder-Decoder、Transformer、Attention等。
1.4.2. 模型架构
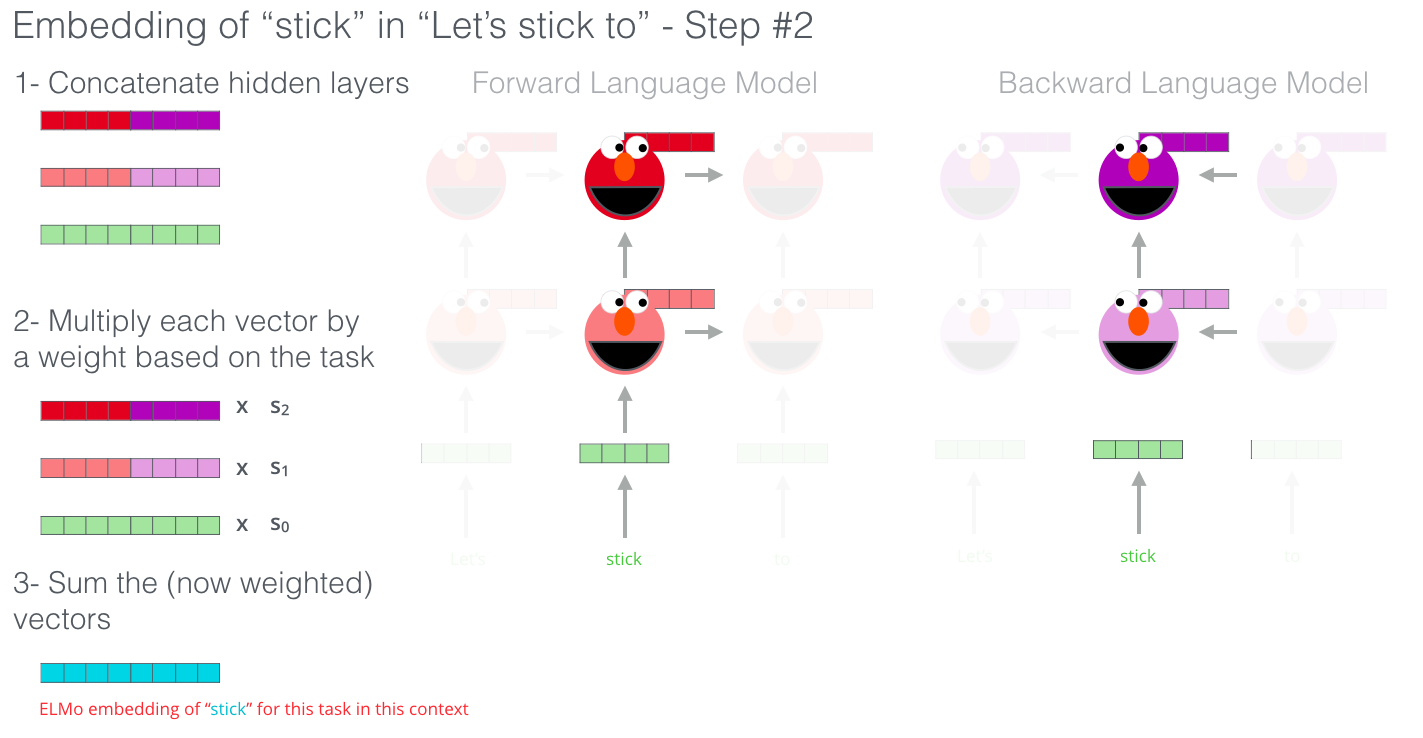
word2vec只是利用了词共现,每个词的表示还是唯一的。但每个词在不同上下文环境下语义差别很大,例如"苹果”既可以表示水果,也可以表示公司,用同一个词向量表示显然是不合理的。此时动态词向量技术应运而生,例如ELMo,利用双向LSTM生成动态词向量。GPT和BERT也是预训练技术的重要代表工作,我们将在后文介绍。
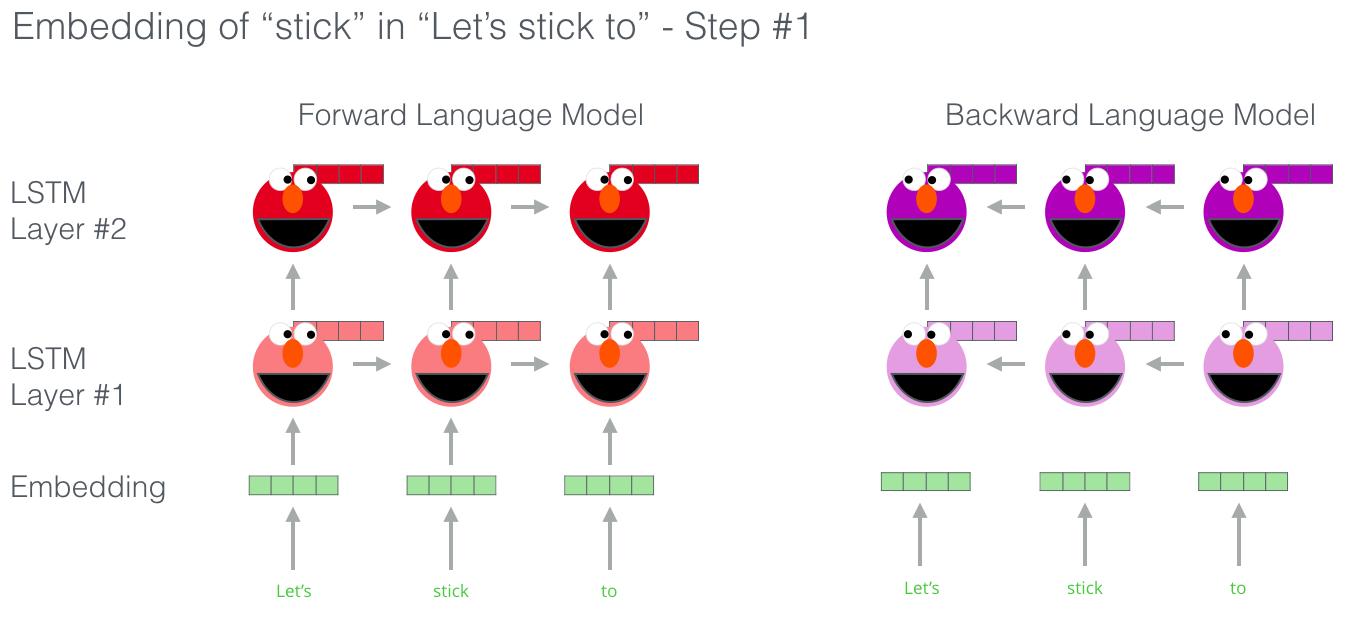
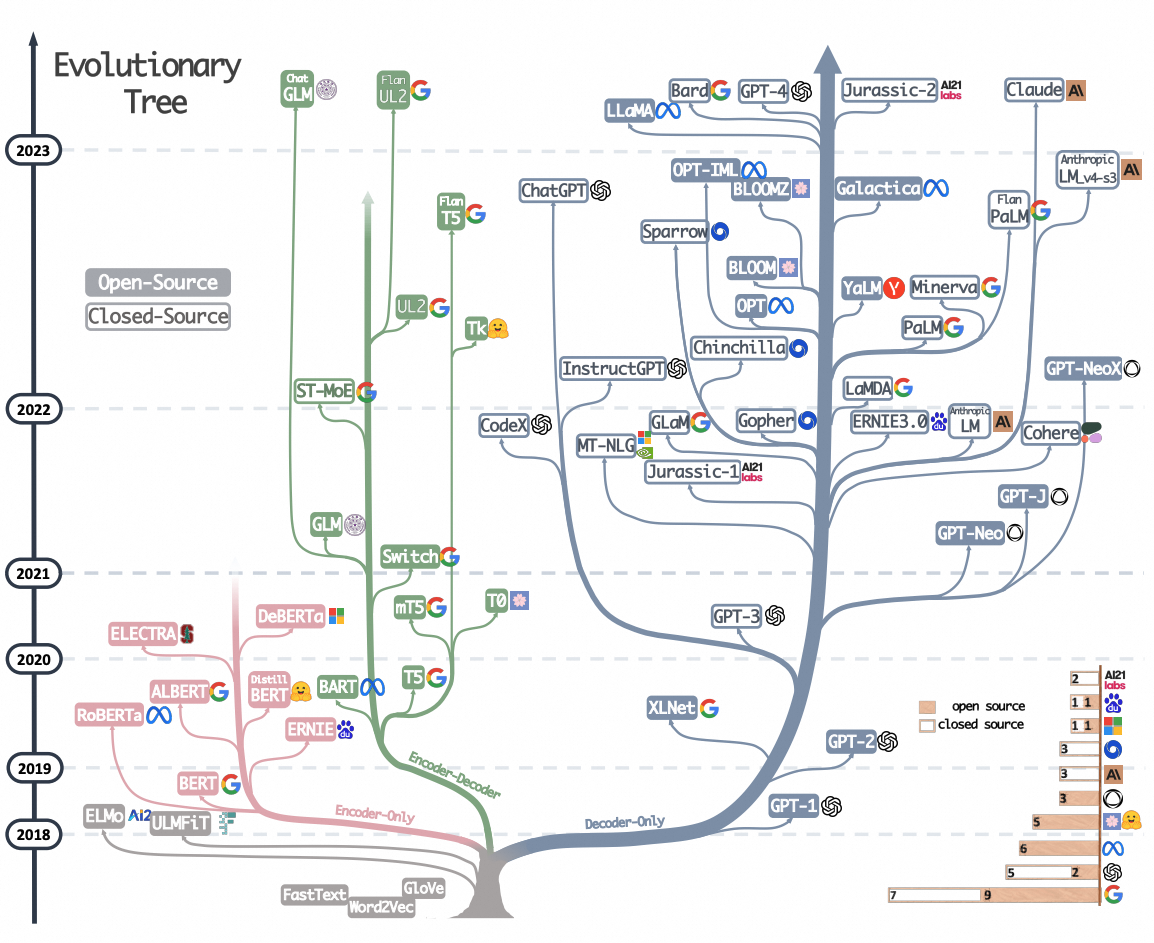
1.5. 大语言模型阶段(2023~)
1.5.1. 阶段特点
从2023年起,目的是让机器能听懂人的命令、遵循人的价值观。其特性是在第一个阶段把过去的两个阶段缩成一个预训练阶段,第二阶段转换成与人的价值观对齐,而不是向领域迁移。这个阶段的突变性是很高的,已经从专用任务转向通用任务,或是以自然语言人机接口的方式呈现。
1.5.2. 模型架构
基于Transformer架构的组合和演化,衍生出了包括仅编码器(Encoder Only)、仅解码器(Decoder Only)以及编解码器结合(Encoder-Decoder)等多种架构。虽然从严格意义上来讲,目前的主流大型模型架构并不包括仅编码器模式,但为了完整性考虑,本文后续部分也将详细阐述该架构。
2. LLM架构基石-Transformer
2.1. 整体架构
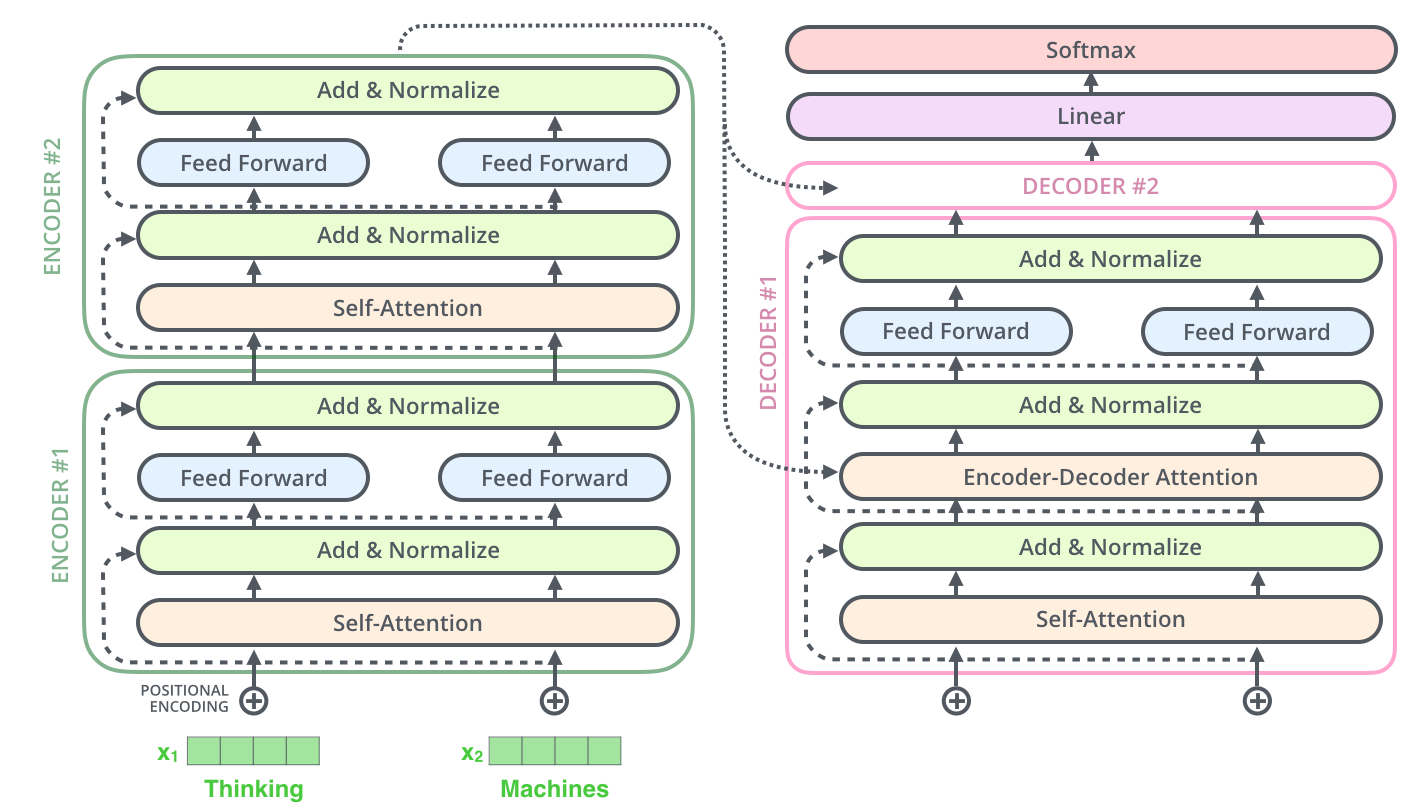
整体是一个encoder-decoder框架:encoder主体由多层self-attention构成,decoder相比encoder多了Encoder-Decoder Attention。
2.2. Encoder
2.2.1. Self-Attention
2.2.1.1. Overview
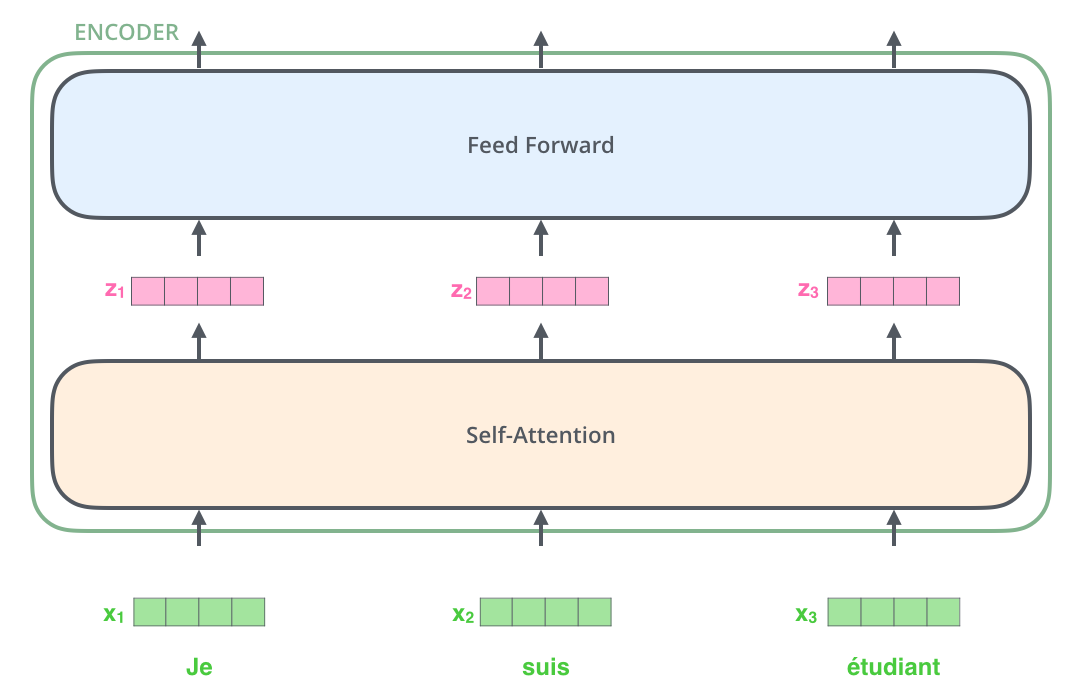
2.2.1.2. Detail
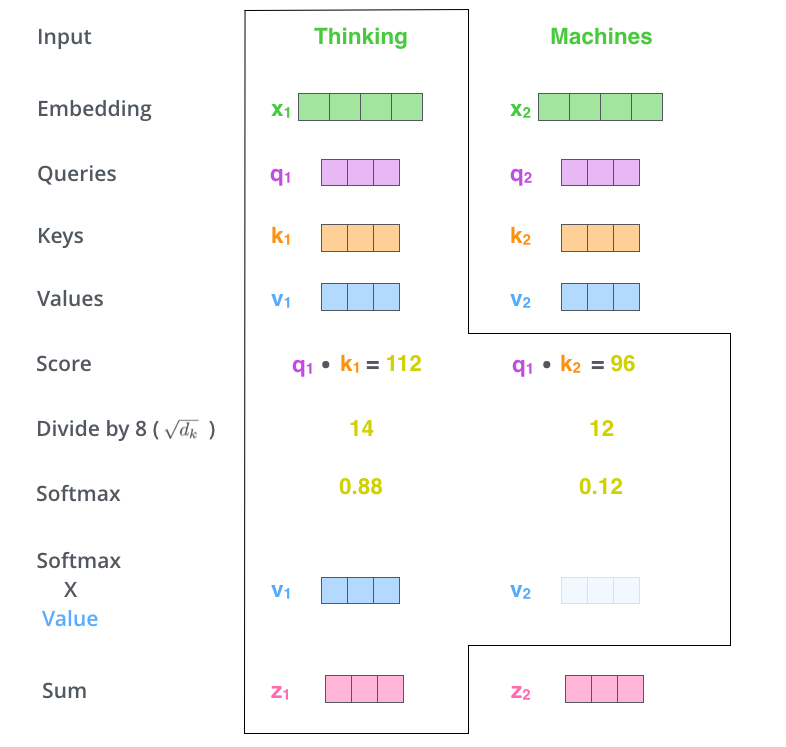
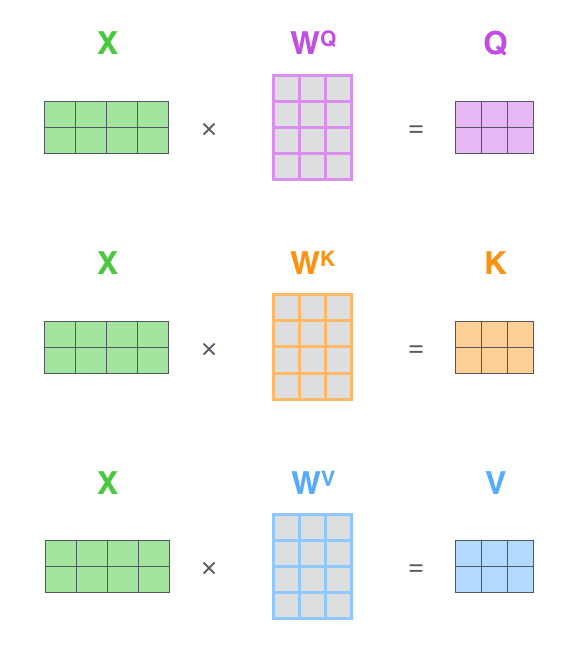
矩阵计算视角:
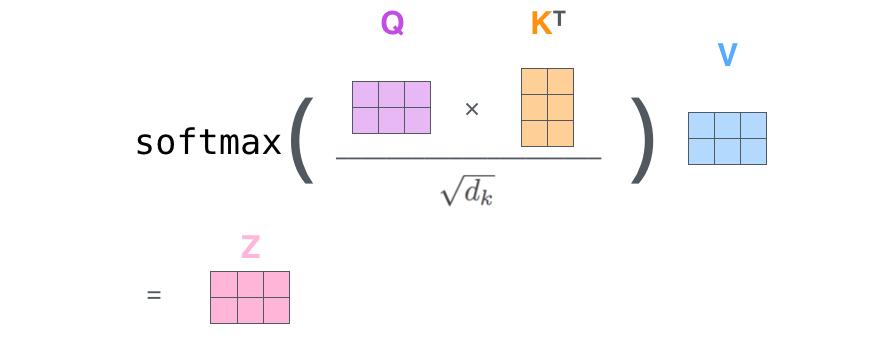
关键设计:Scale
- 为什么要做Scale?
Score是由两个向量内积得到,容易产生较大的值导致落入softmax函数梯度平缓区,容易导致梯度消失。
| |
不scale结果:
| |
scale后结果:
| |
- 为什么是$\sqrt{d_k}$
根据假设$q_i$和$k_i$是两个相互独立,且均值为0,方差为1的随机变量,那么有:


因此$QK^T$除以$\sqrt{d_k}$可以将方差纠正为接近1,这样大部分值都在合理的区间了。
2.2.1.3. MultiHead
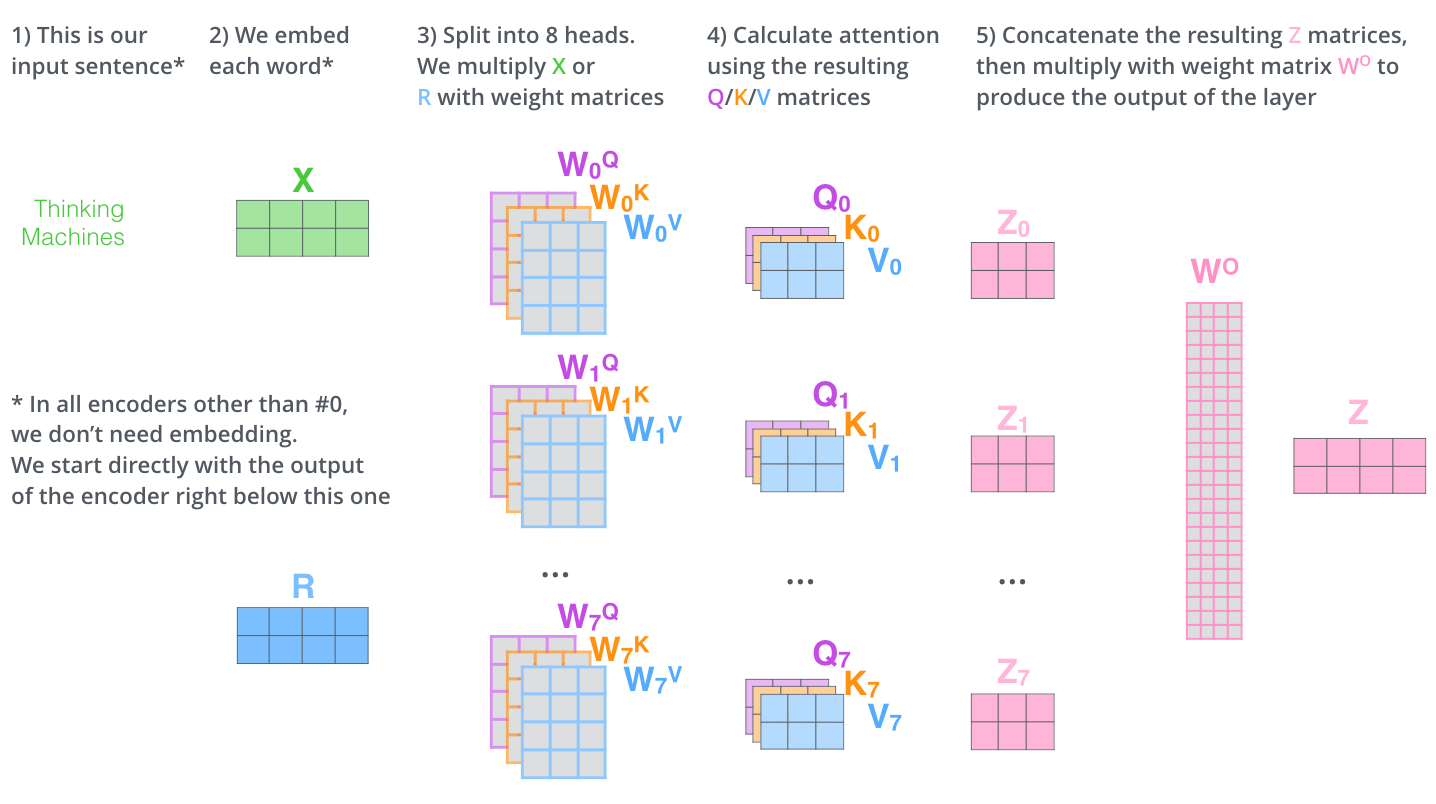
引入MultiHead有两点好处:
- 不同head可以重点关注不同位置的信息。
- 增加了Attention Layer的表示子空间。

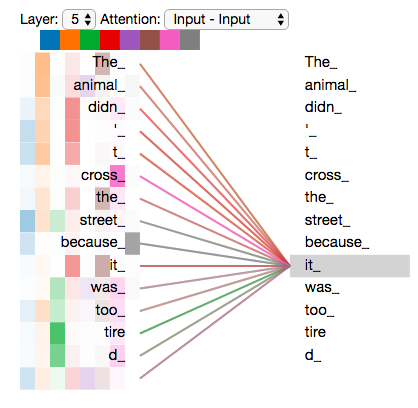
筛选其中2个head结果 8个head完整结果
2.2.2. Position Embedding
上述self-Attention结构没有建模位置信息,而“顺序”对于NLP至关重要,比如“吃饭不”和“不吃饭”句子含义差异很大。
计算公式:
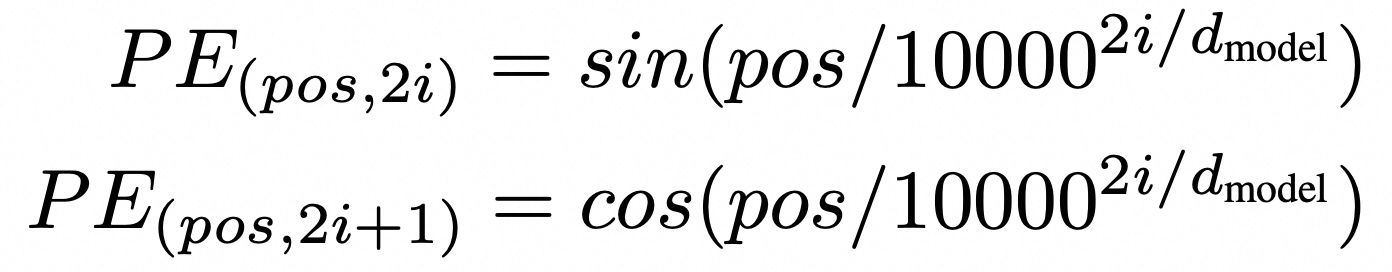
可视化:
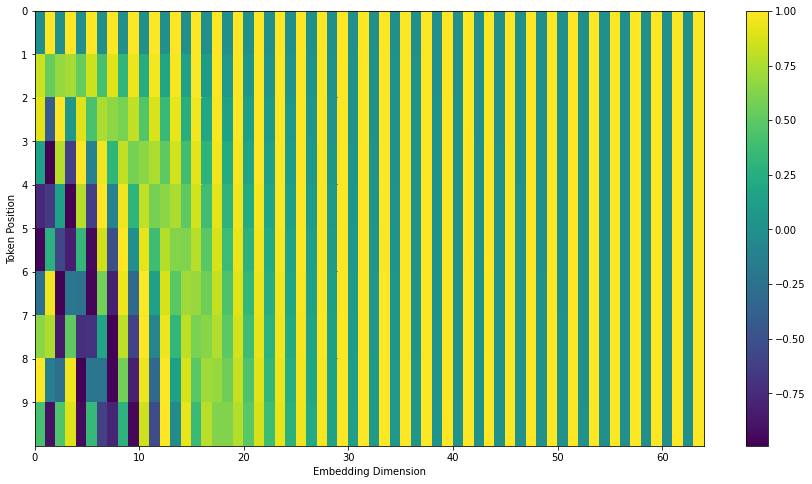
位置编码设计成这样有以下几个考虑:
- sin/cos自变量范围较小,很难重复,基本可以保障编码的唯一性。
- 对输入长度没限制,可以无限扩展
- 位置编码不仅表示绝对位置,也蕴含相对位置。
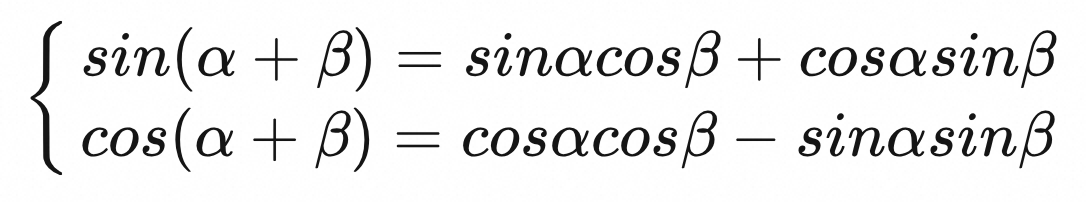
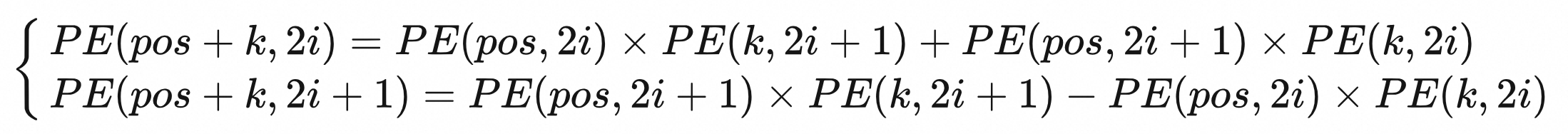
pos+k的位置编码可以由pos位置和k位置线性组合得到。
问题1:为什么同时采用sin和cos?
个人认为是为了利用三角函数特性,能够蕴含相对位置。
问题2:sin-cos编码比绝对位置embedding更好么?
在文中提过绝对位置Embedding和sin-cos位置编码效果类似,具体还需要根据任务效果来选择。比如BERT中就采用了绝对位置Embedding。
2.2.3. Add & Normalize
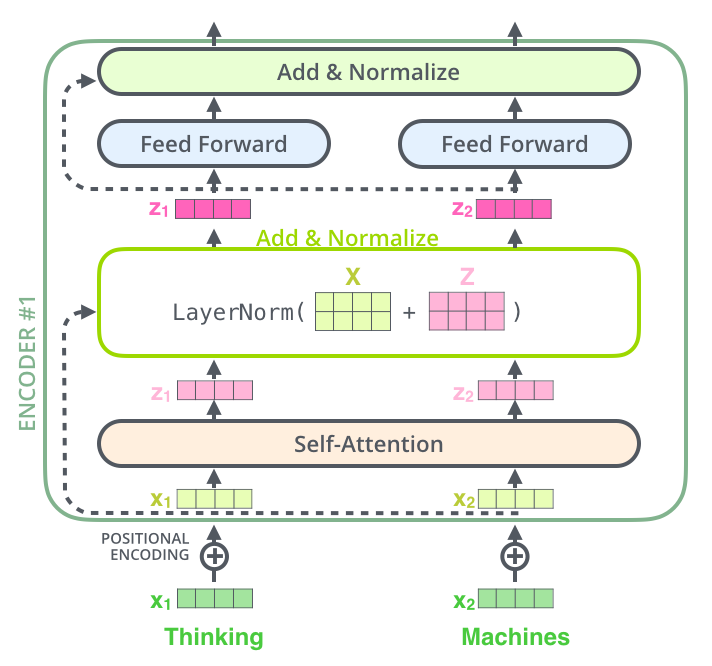
残差和LN都能帮助缓解梯度消失问题,下面是一个实践经验:
我们分析梯度值发现multi-head target attention参数的梯度值量级非常小,影响模型收敛速度。layer norm可以实现对梯度的平移和缩放,加入layer norm后梯度值被放大,最终带来1~2千分点的提升。
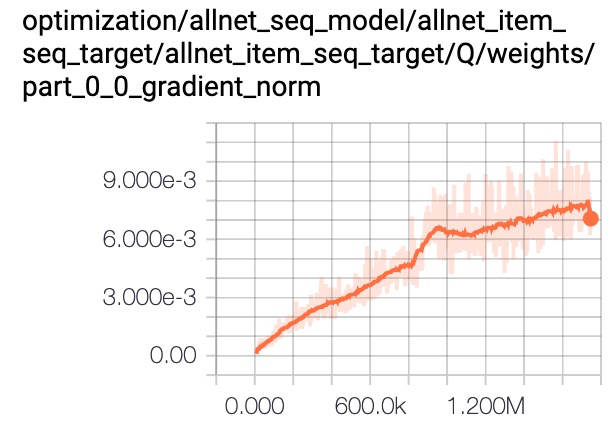
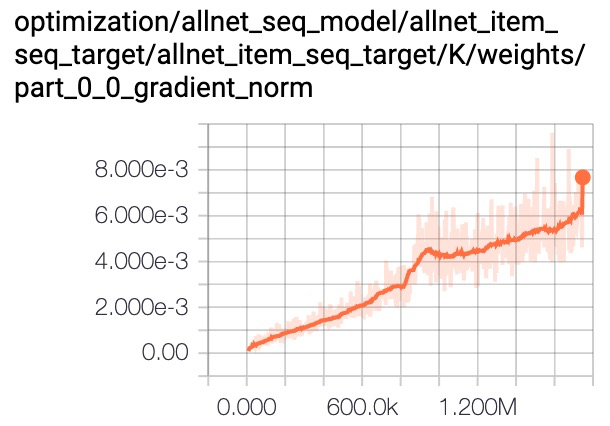
a) Multi-head Target Attention
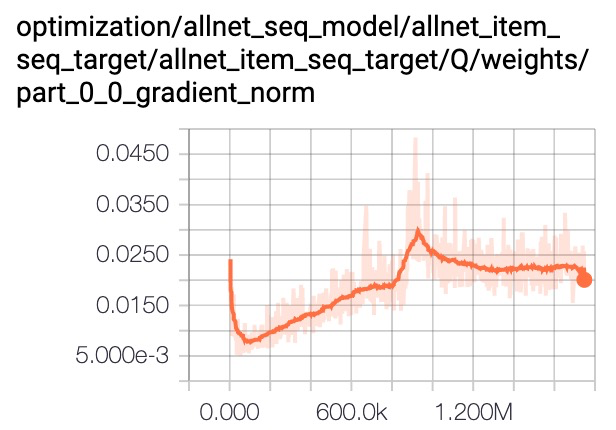
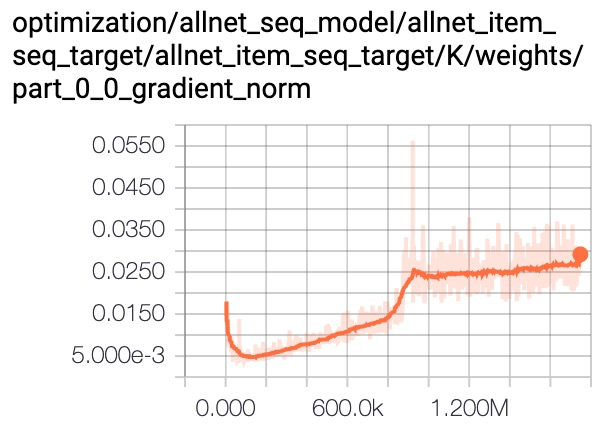
b) Multi-head Target Attention With Layer Norm
2.3. Decoder
Decoder与Encoder架构上有几个区别:
- decoder多了个Encoder-Decoder Attention,为了在生成的时候结合输入信息。具体操作是Encoder最后一层表达生成$K$和$V$, 然后Decoder生成$Q$, 其他操作就是Multihead Attention。
- decoder时self-attention只能用前面已生成的序列
- 解码时一般有greedy和beam search两种方式。
3. LLM架构范式
3.1. Encoder-Only
Encoder-Only架构又称之为自编码(AutoEncoder)
3.1.1. BERT
3.1.1.1. 动机
在BERT(Bidirectional Encoder Representations from Transformers)出来前,动态词表示有两个研究分支:一是feature-based,代表工作为ELMo(Embeddings from Language Models),利用双向LSTM语言模型建模词表示,作为下游任务的特征使用。二是fine-tuning,代表工作是GPT(Generative Pre-trained Transformer),利用单向Transformer训练语言模型,与下游任务配合fine-tune。
ELMo和GPT在训练的时候都是单向语言模型,用上文或者下文来预测下个词。上下文理解能力对很多任务至关重要,BERT提出MLM (Masked Language Model)建模上下文理解能力。简单来说,就是随机挖掉中间词,让模型通过上下文信息预测中间词的方式建模上下文信息,而Transformer本身就具备每个位置看到所有位置信息的能力。
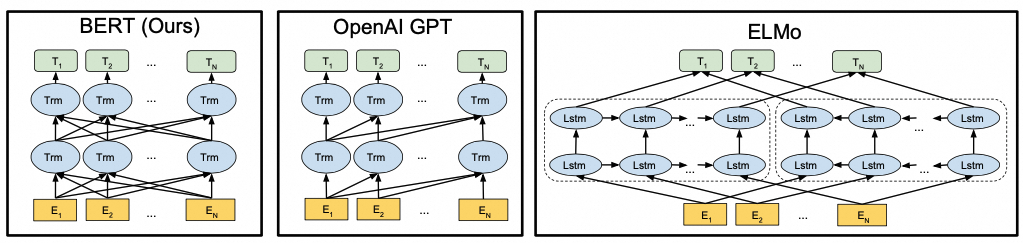
3.1.1.2. 两个训练任务
任务1:MLM
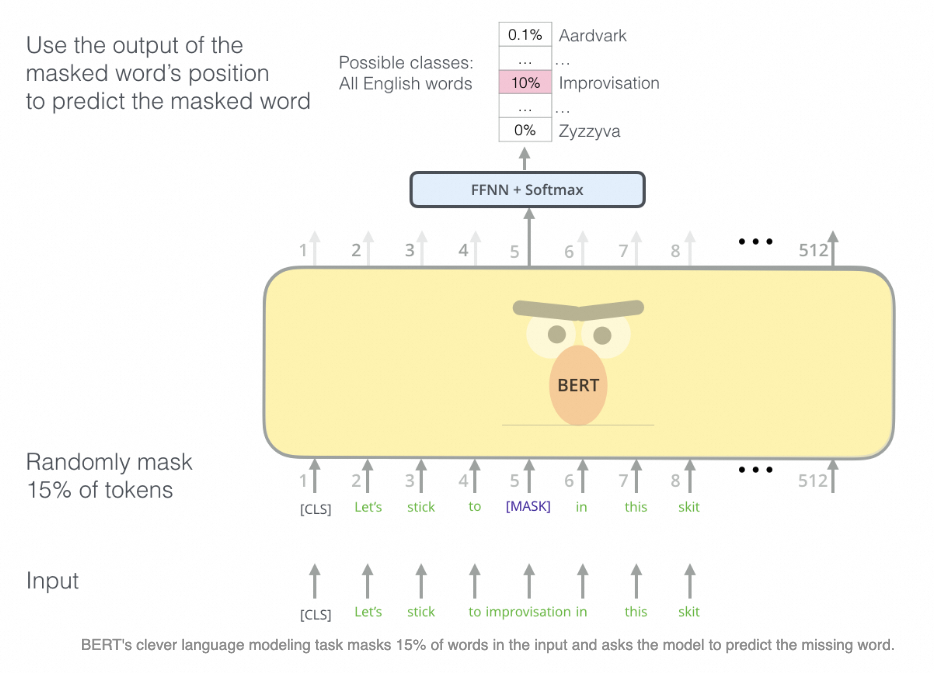
引入两个特殊token:[CLS]代表分类符,训练NSP和下游Fine-tuning时都会用到;[MASK]代表该位置token被mask掉。
核心设计-Mask:随机mask 15%的词级别tokens,该位置替换为[MASK]标识,让模型根据上下文预测该词。但是考虑到下游应用并没有[MASK]标识,因此将随机选中的tokens以100%概率替换为[MASK],10%概率保留原词,10%概率替换为随机词。
问题1:为什么不保留100%的[MASK],而只保留100%呢?
除了文中提到的下游应用没有[MASK]带来不一致,另外也避免[MASK]只学习到训练语料词的分布,比如训练数据有20%的词都是Is,那么[Mask]也倾向于有20%概率预测Is。
问题2:为什么随机替换随机词?会对影响训练么?
保留随机词有两个好处:一是增加模型鲁棒性,当见到脏数据模型也有能力做预测;二是会迫使模型利用上下文进行预测当前词。这类数据占比15% x 10% = 1.5%,数量很少,对模型训练影响不大。
不同Mask策略实验结果如下:
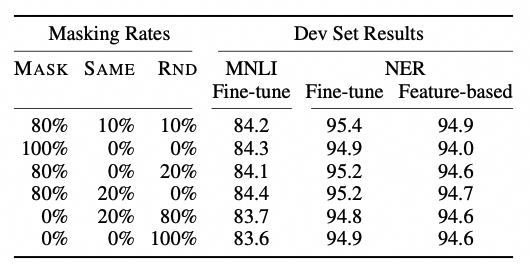
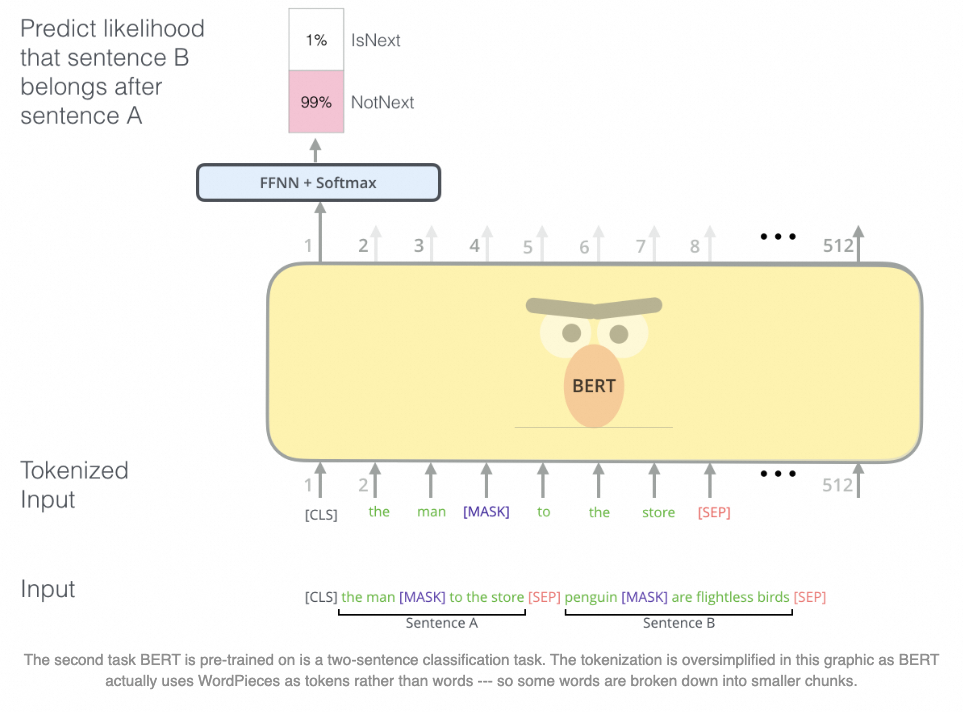
任务2:NSP (next sentence prediction)
引入句子分隔符[SEP]
有些任务需要句子级别依赖,例如阅读理解。为了建模长句子依赖,BERT引入NSP任务,判断B句子是不是A句子的下文。A句子下文50%概率保留原文作为正样本,50%概率随机替换别的句子作为负样本。
3.1.1.3. BERT For fine-tuning
BERT所有参数都会参与下游任务联合训练。
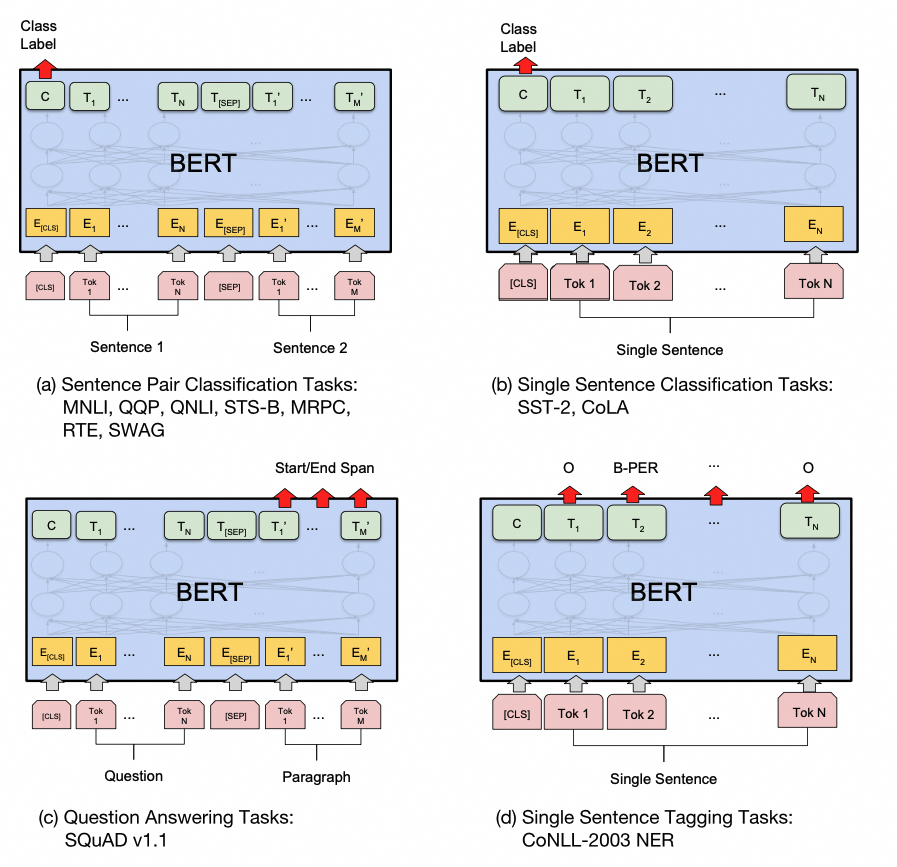
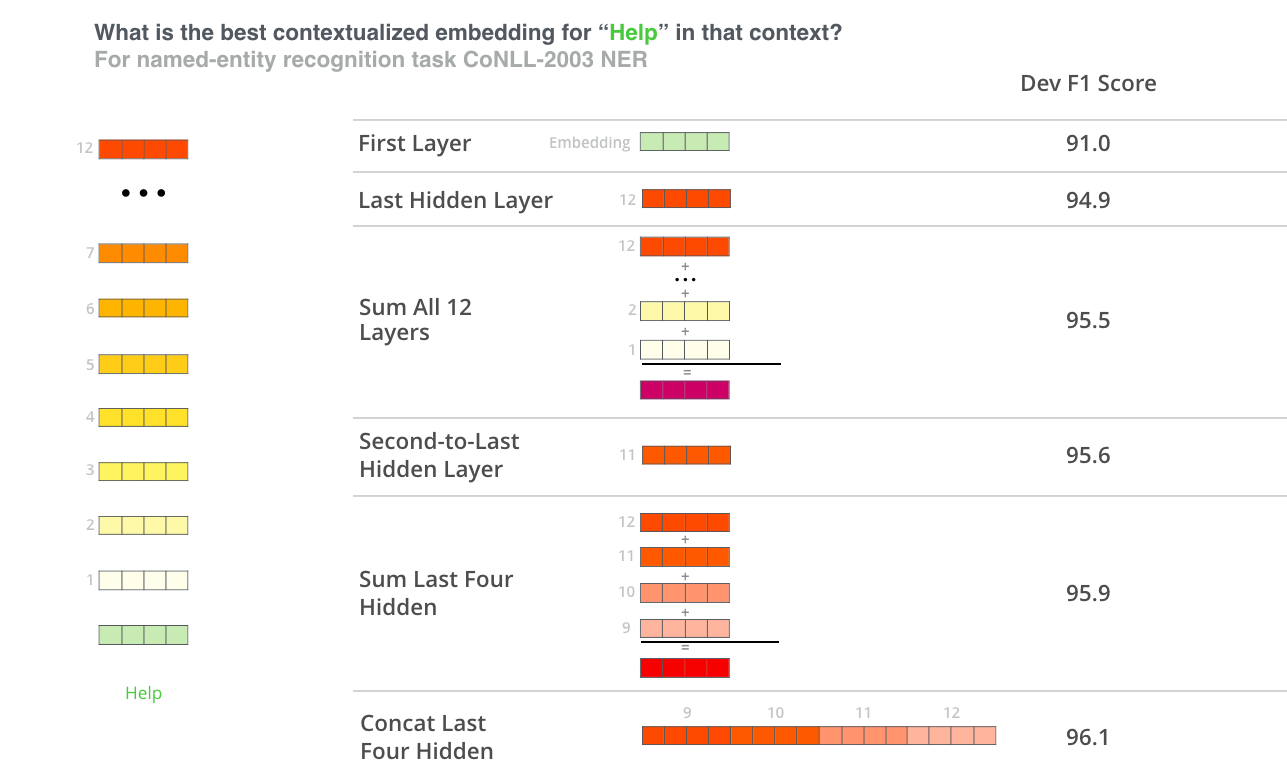
3.1.1.4. BERT for feature extraction
只拼接最后4层就能获取很高的准确率。
3.2. Decoder-Only
Decoder-Only架构又称为自回归(AutoRegressive)。
3.2.1. Causal Decoder
因果解码器架构采用单向注意力掩码,以确保每个输入 token 只能关注过去的 token 和它本身。输入和输出token通过解码器以相同的方式进行处理。代表工作是GPT系列。
更好理解GPT架构执行流程,可以参考一个可视化网站:https://bbycroft.net/llm
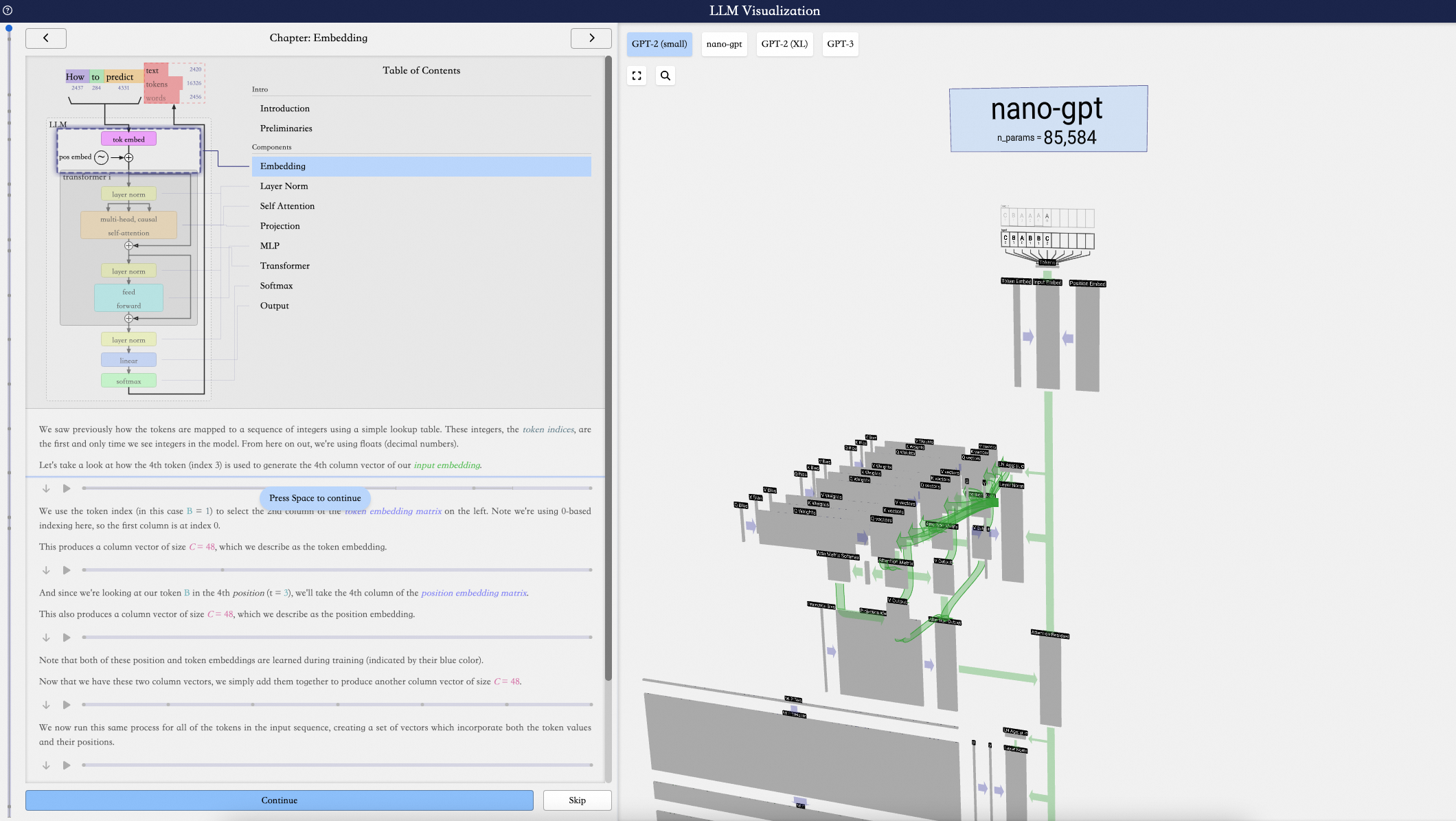
3.2.1.1. GPT-1:半监督学习
GPT-1是通过半监督学习方式解决NLP任务,即无监督的预训练+有监督的微调。
GPT-1是一个基于Transformer的前向语言模型。在生成下一个单词时,Transformer只能读到左边已生成的部分。
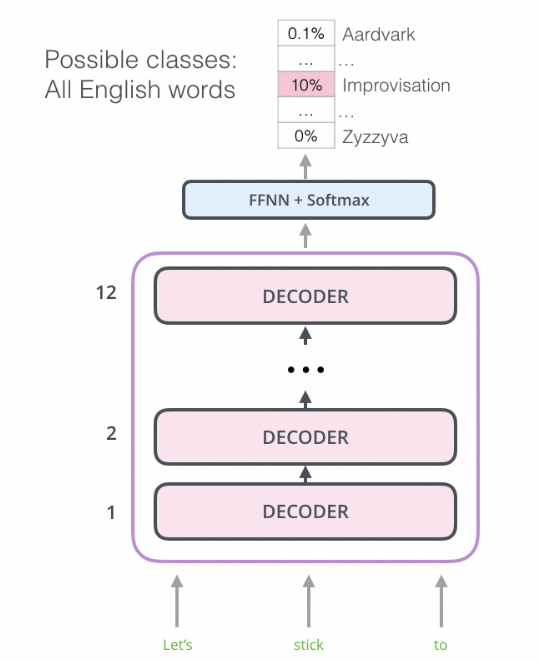
由于每个位置只能看到前面的序列,因此采用了Masked Self-Attention,这和BERT将不可见词替换为[MASK]标志不同。
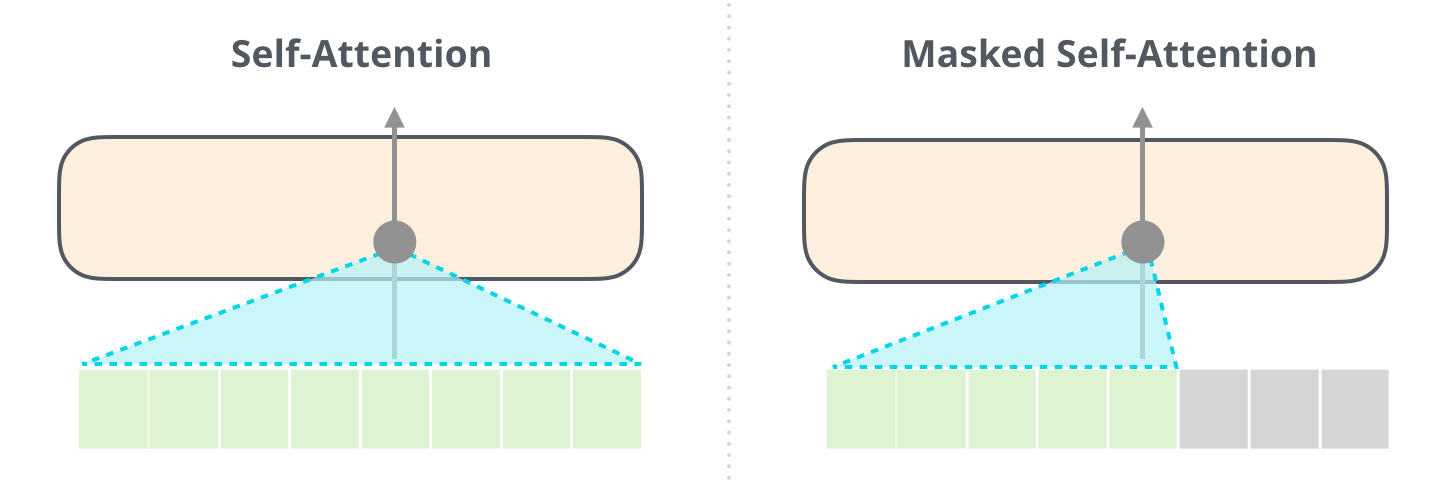
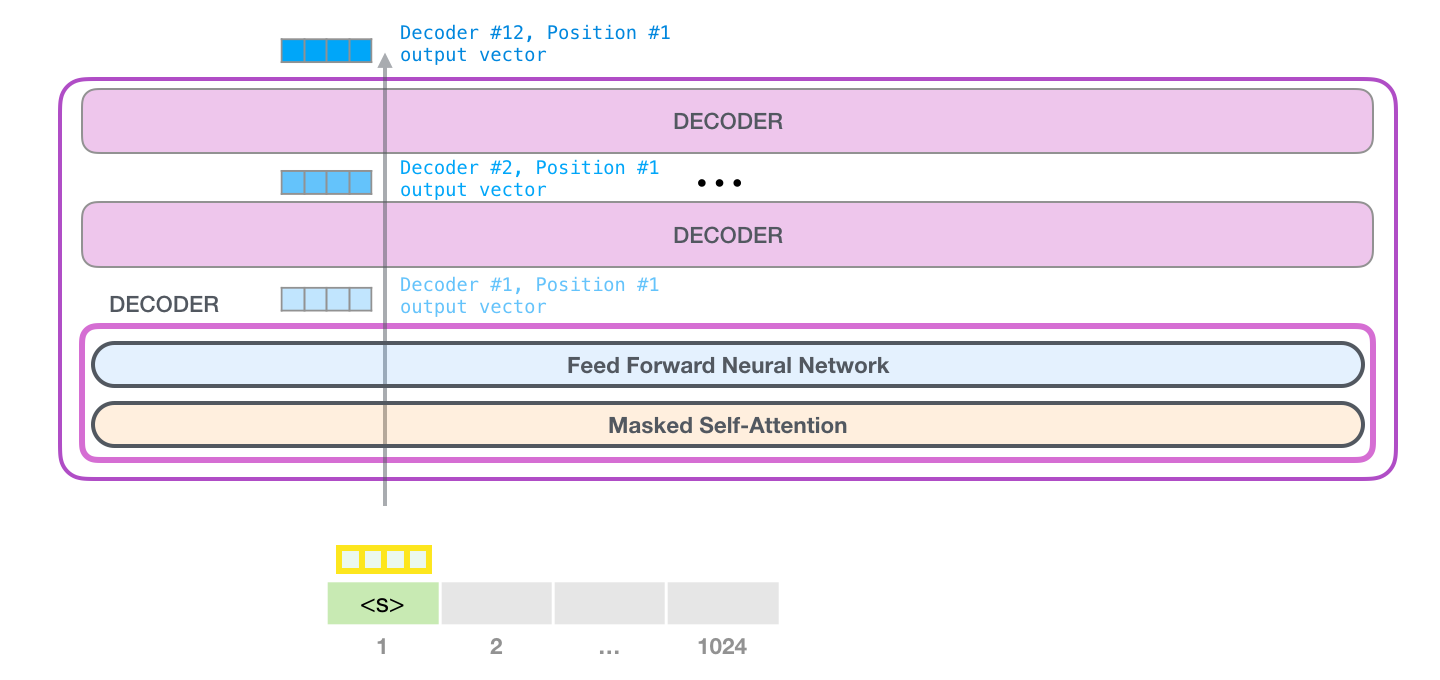
计算到第2个位置时,第一个位置产生的K和V可以复用,无需重复产出。
其Fine-tune的模式如下:
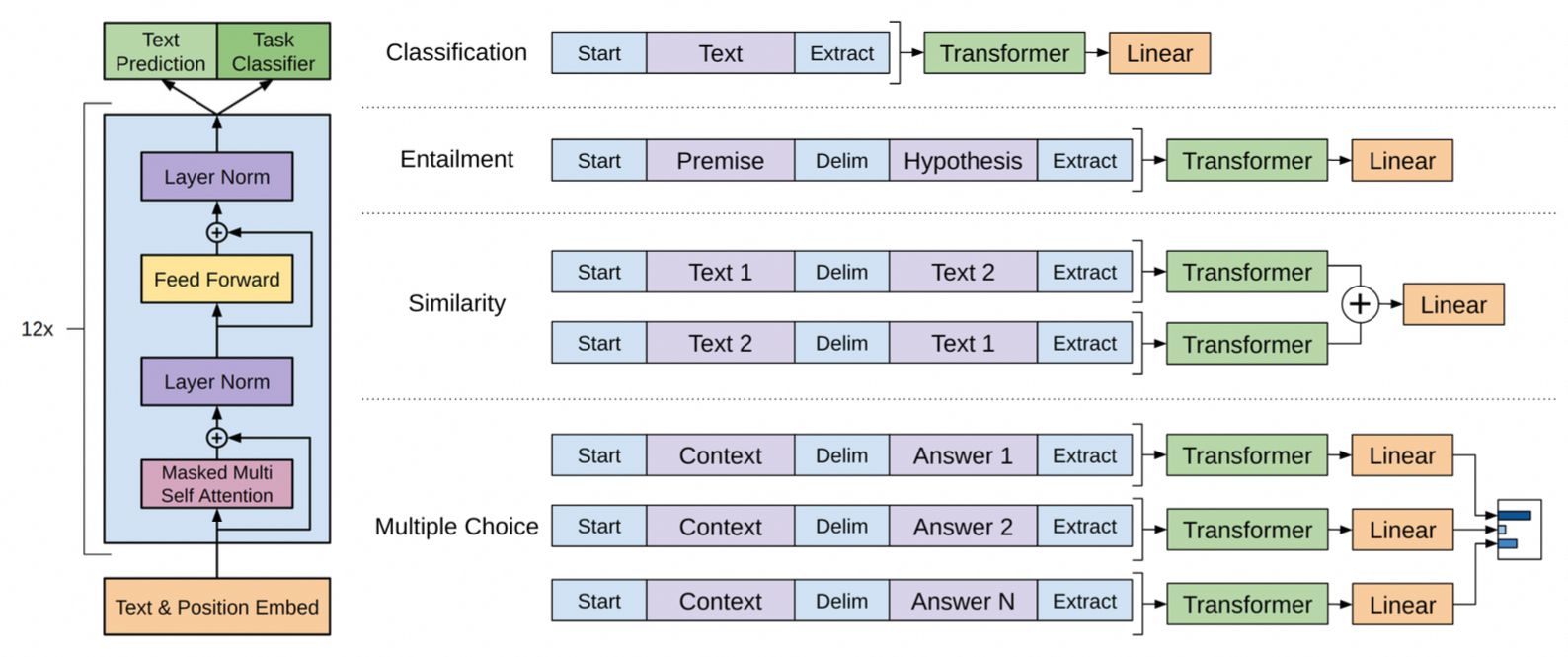
有两个关键设计:
- 由于预训练阶段没有区分句子顺序能力,例如A句子后接B句子,那么语义上可能会学到B是A的下文,而对于句子相似度任务这种顺序会影响模型判断,因此同时保留A-B和B-A两种输入关系。
- fine-tuning时也引入语言模型任务作为辅助任务,既能提高模型泛化能力,也能加速任务收敛速度。
GPT-1开始关注到decoder-only架构在解决zero-shot问题有一定优势,为GPT-2埋下伏笔。
3.2.1.2. GPT-2:多任务学习
当时主流的NLP范式是预训练+微调,这种方式成本较高,而且缺乏泛化能力,每个新任务都需要标注数据进行fine-tune。GPT-2的核心尝试不微调,直接通过预训练学习多任务能力,无需微调!GPT-2有两个核心设计:一是将任务描述也作为模型的输入(即prompt),二是大力出奇迹。
将任务作为模型的输入是一个天才的想法,是NLP范式的一个巨大转变,核心思路一个公式就能讲清楚:

对于翻译任务,输入可以定义为: (translate to french, english text, french text)
对于阅读理解任务,输入可以定义为:(answer the question, document, question, answer)
….
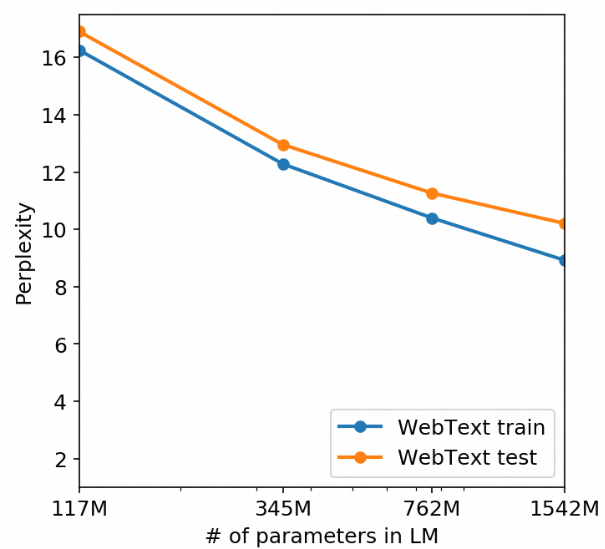
从架构上,GPT-2与GPT-1一致,参数量增加了10几倍。GPT-1是117M,GPT-2是1.5B。从各种数据集合的表现来看,效果随着参数量增加也显著提升。
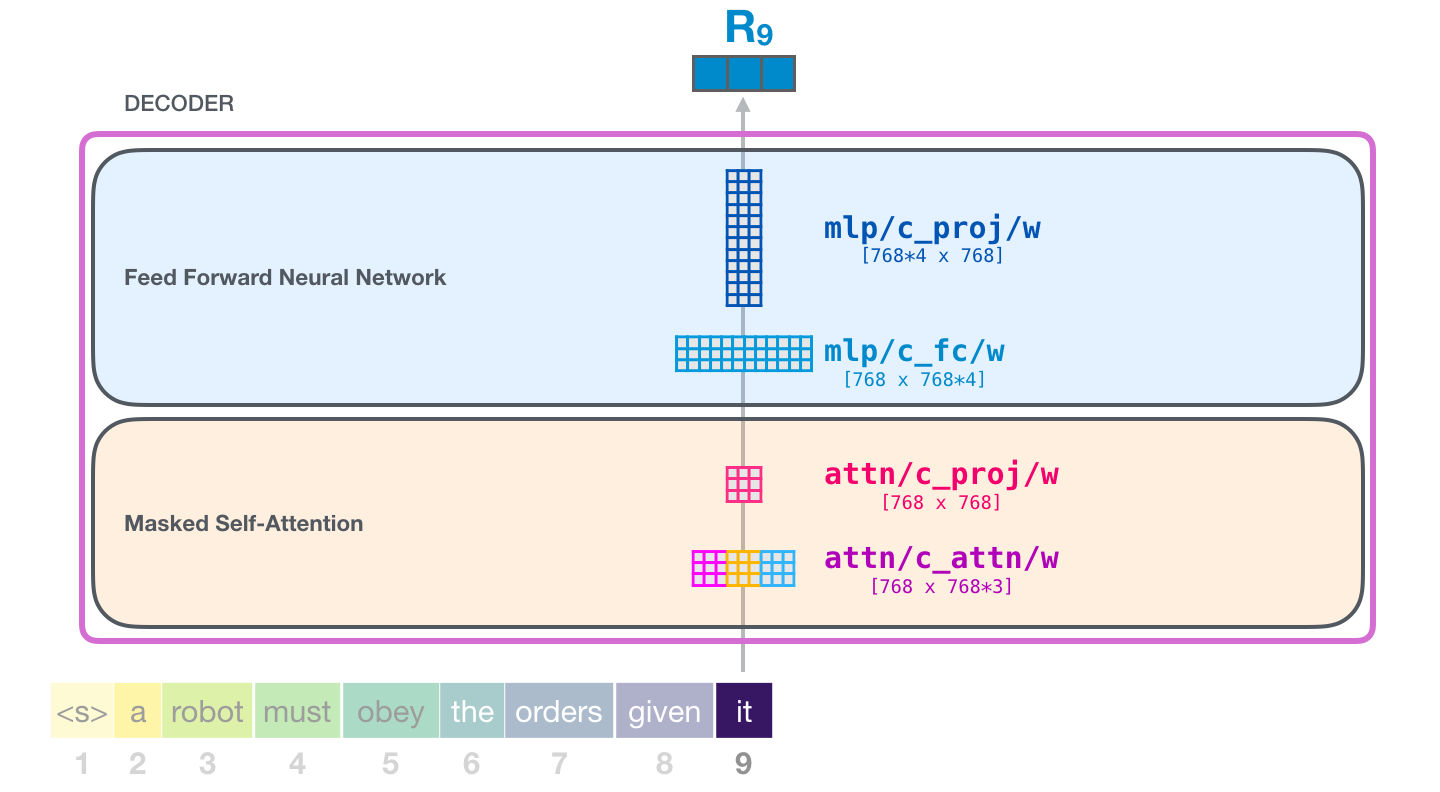
以117M模型为例,每一层的decoder参数如下:
整体的参数量计算如下:
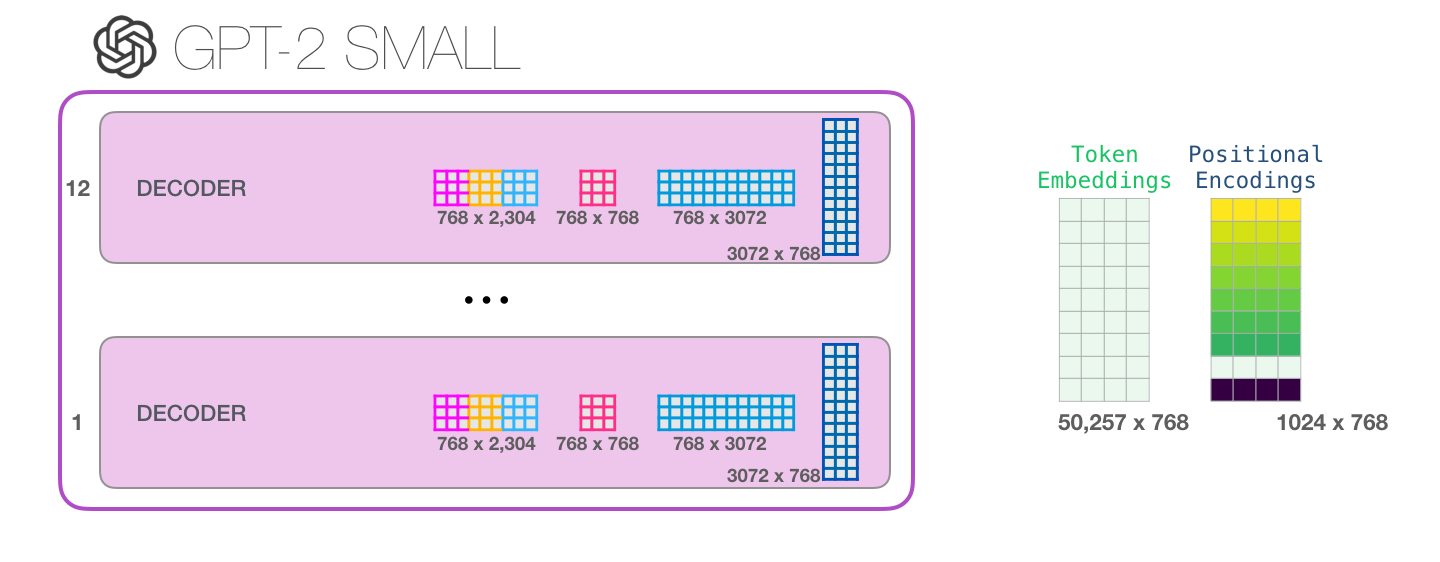
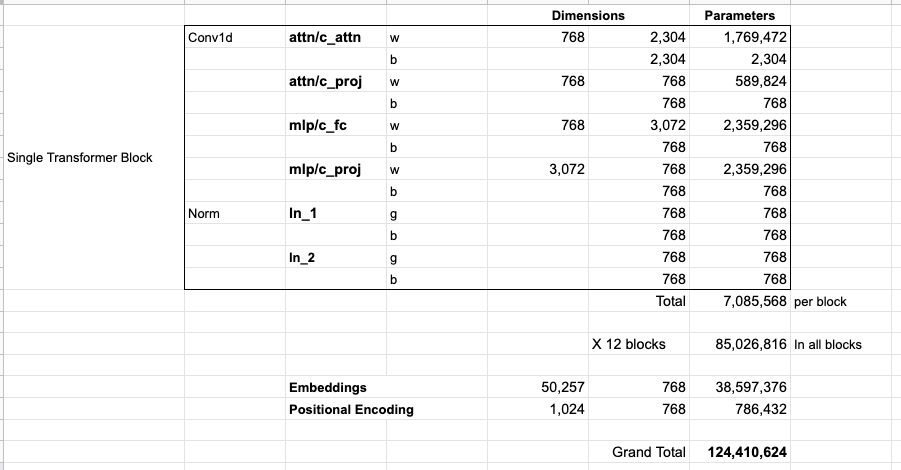
最终计算出124M,和论文提到的117M有一些出入。
小知识:GPT输入最小粒度为什么是token,而不是word呢?
GPT采用的输入切分方式是BPE(Byte Pair Encoding)分词:通过不断地合并出现频率高的子词,BPE分词算法可以得到一组细粒度的子词单元,这些子词单元可以更好地表示原始文本中的词汇和词组。由于BPE分词算法是基于频率的统计方法,它可以自适应地根据特定文本的特点生成合适的子词单元,从而在不同的自然语言处理任务中取得良好的效果。所以输入粒度并不是word概念。
3.2.1.3. GPT-3:上下文学习
GPT-2通过将任务描述加入到输入中,让模型能够根据描述解决特定任务。但是这种做法上限较低,即使是人在解决新问题时也很难处理好。但有几个示例后,人能够根据知识和示例快速学习。GPT-3的提出就是这种动机,核心设计有两个:一是引入上下文学习(In-context learning, ICL),大大提高了模型能力,尤其是处理复杂任务的能力;二是极致的暴力美学。
我们再回顾下这句话“人能够根据知识和示例快速学习”,这种根据知识和示例快速学习的想法并不是第一次提出。Meta-Learning有异曲同工之妙。假设有一个 task 的分布,我们从这个分布中采样了许多 task 作为训练集。我们希望 meta learning 模型在这个训练集上训练后,能在这个分布中所有的 task 上都有良好的表现,即使是从来没见过的 task。
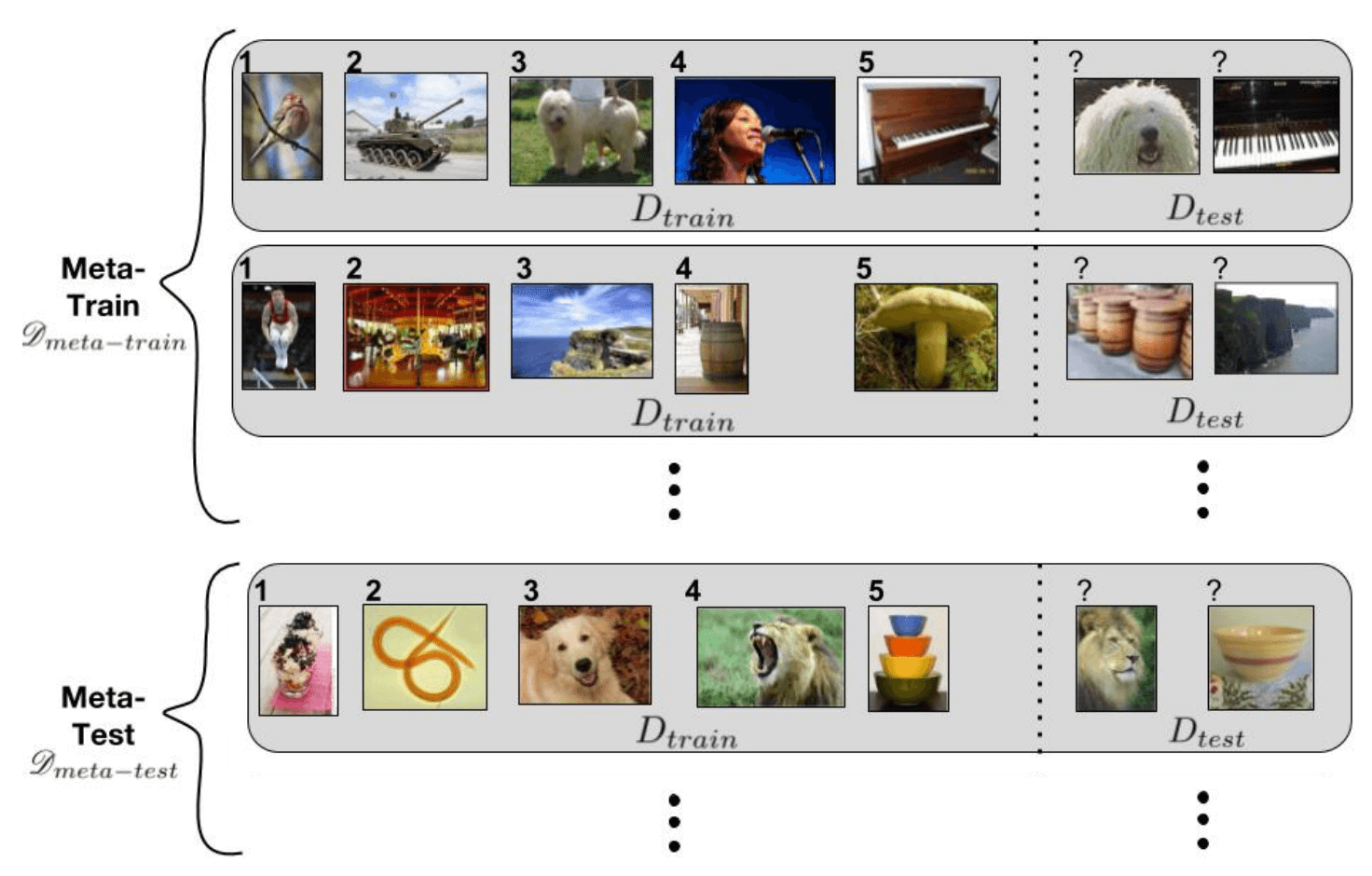
MAML是比较经典的工作,目的是学习一个好的初始化,使得模型能快速适应新任务:
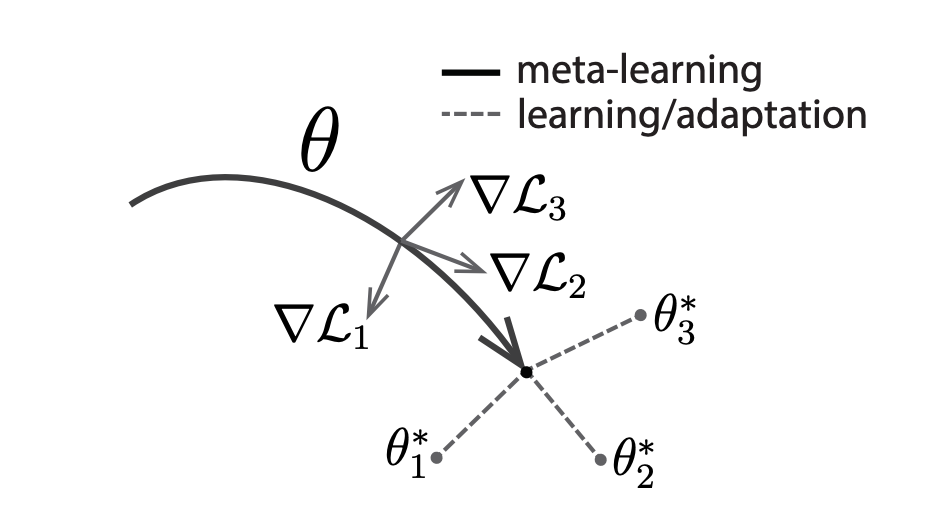
其迭代分为内循环和外循环两个框架:

外循环负责筛选一批任务进行一次梯度更新,内循环负责为每个任务计算更新梯度,但不会立马更新该任务梯度,而是在外循环中一次更新多个任务的梯度。这样的好处就是避免参数过于偏向最近训练的任务。
回到GPT-3上来,上下文分为三种:Zero-shot、One-shot和Few-shot:

对应到Meta-Learning框架上:
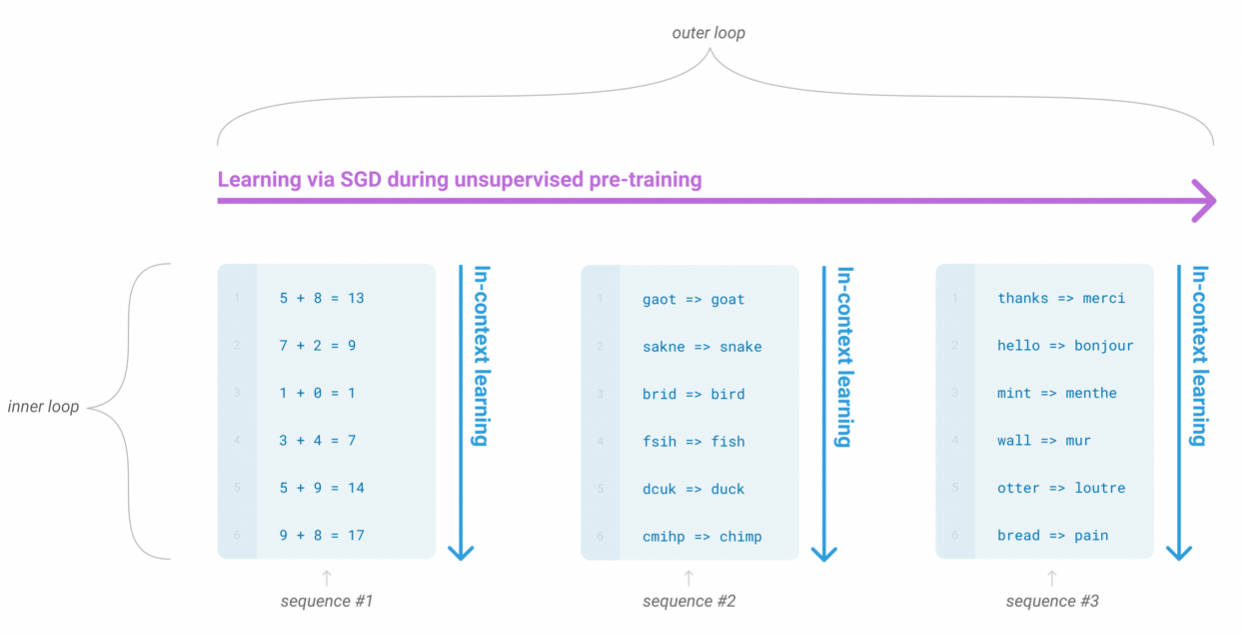
不过GPT-3相比Meta-Learning是个更优雅的范式。面对新任务时,无需训练参数,只需要在输入给任务描述和少量示例即可。
GPT-3另一个特点是极致的暴力美学:
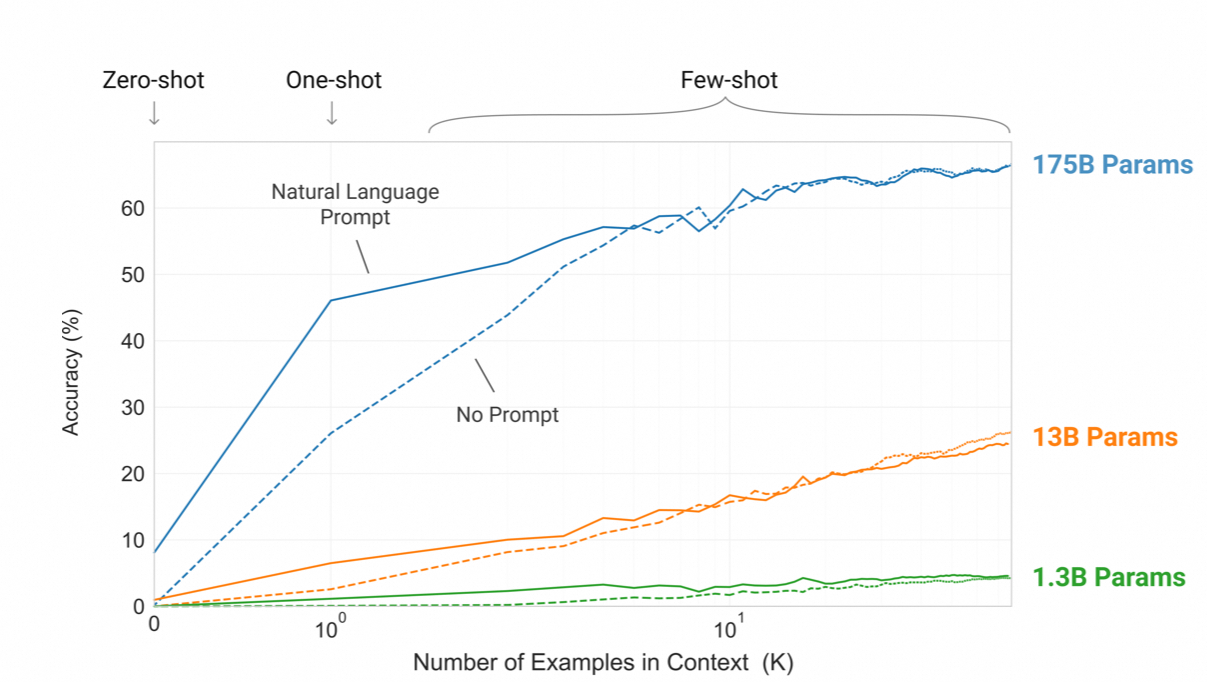
有两个发现:一是参数量对模型性能有极大影响,而是one-/few-shot对参数量大的模型性能提升更显著。
原文细节非常多,这里不再赘述。
3.2.2. Prefix Decoder
前缀解码器架构(也称非因果解码器架构)修正了因果解码器的掩码机制,以使其能够对前缀token执行双向注意力,并仅对生成的 token 执行单向注意力。代表工作是GLM(General Language Model)系列。
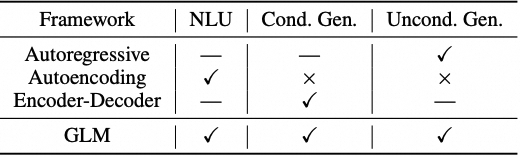
回归模型从左到右学习语言模型,适合于长文本生成和少样本学习,但不能捕捉上下文词之间的双向依赖关系。
自编码模型通过去噪目标学习双向上下文编码器,适合于自然语言理解任务,但不能直接用于文本生成。
编码器-解码器模型结合了双向注意力和单向注意力,适合于有条件的生成任务,如文本摘要和回复生成。
这三类语言模型各有优缺点,但没有一种框架能够在所有的自然语言处理任务中都表现出色。因此清华提出一个通用架构,想结合这三种框架的优点。
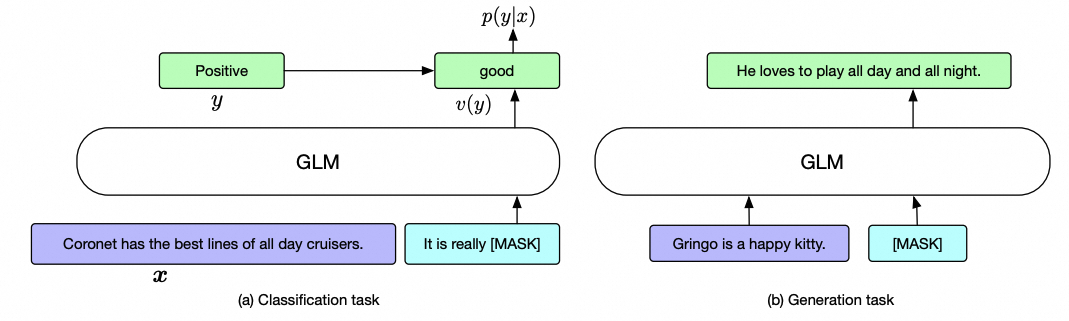
GLM有两个关键设计:一是随机挖掉若干个子序列,并打乱顺序做生成;二是二维位置编码。位置也是为了前者服务。
本质上GLM还是个自回归模式,只是预测的并不是句子的下个词,而是中间的序列。并且通过打乱机制让模型学到上下文能力。

3.3. Encoder-Decoder
Encoder-Decoder的代表工作BART,T5和Switch Transformer等,这里只介绍BART。
BART(Bidirectional and Auto-Regressive Transformers)设计如下:
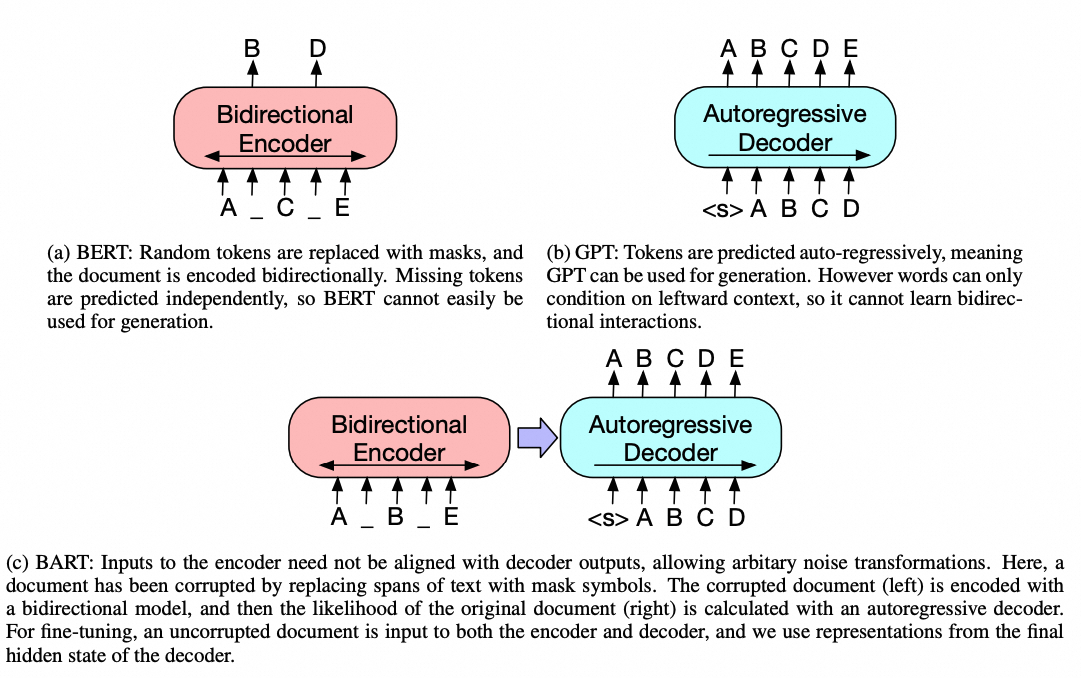
除了上述架构,还有个比较重要的点是对输入加了噪声。
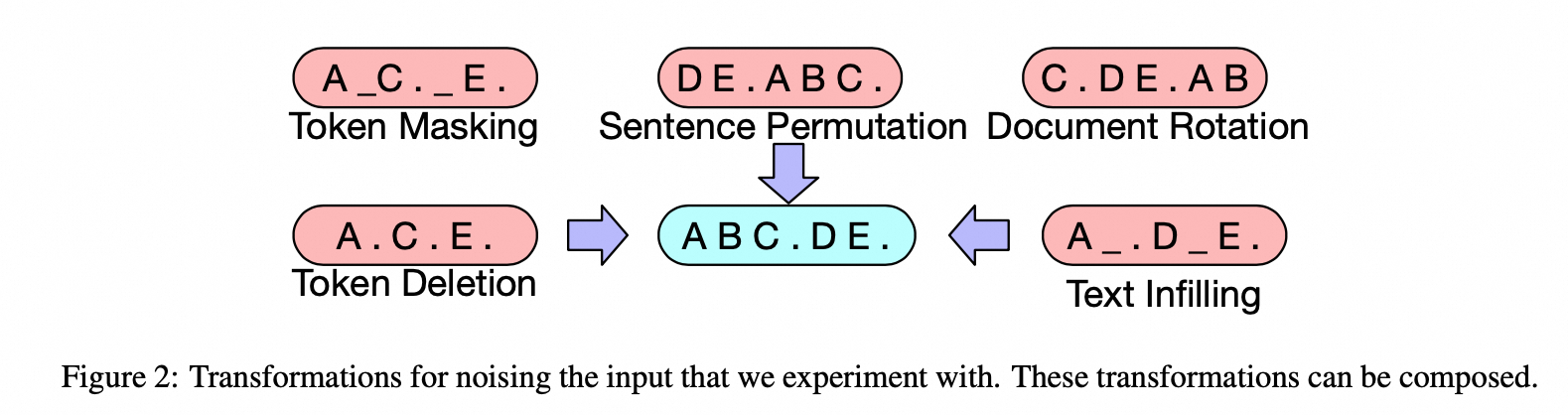
3.4. MOE
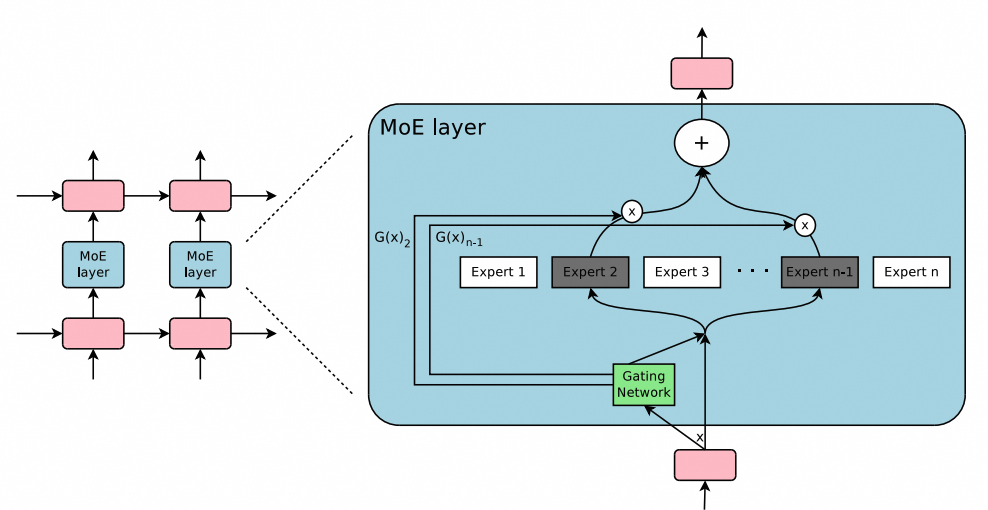
对于上述架构,我们可以通过专家混合(MoE)扩展来进一步扩展它们,在这种扩展中,每个输入的一部分神经网络权重被稀疏激活,例如Switch Transforme。MoE的主要优点是它是一种灵活的方式来扩大模型参数,同时保持恒定的计算成本。有研究表明,通过增加专家数量或总参数大小可以观察到显著的性能改进。尽管有这些优点,但由于路由操作的复杂、硬切换特性,训练大型MoE模型可能会遇到不稳定性问题。
3.5. 架构选择总结
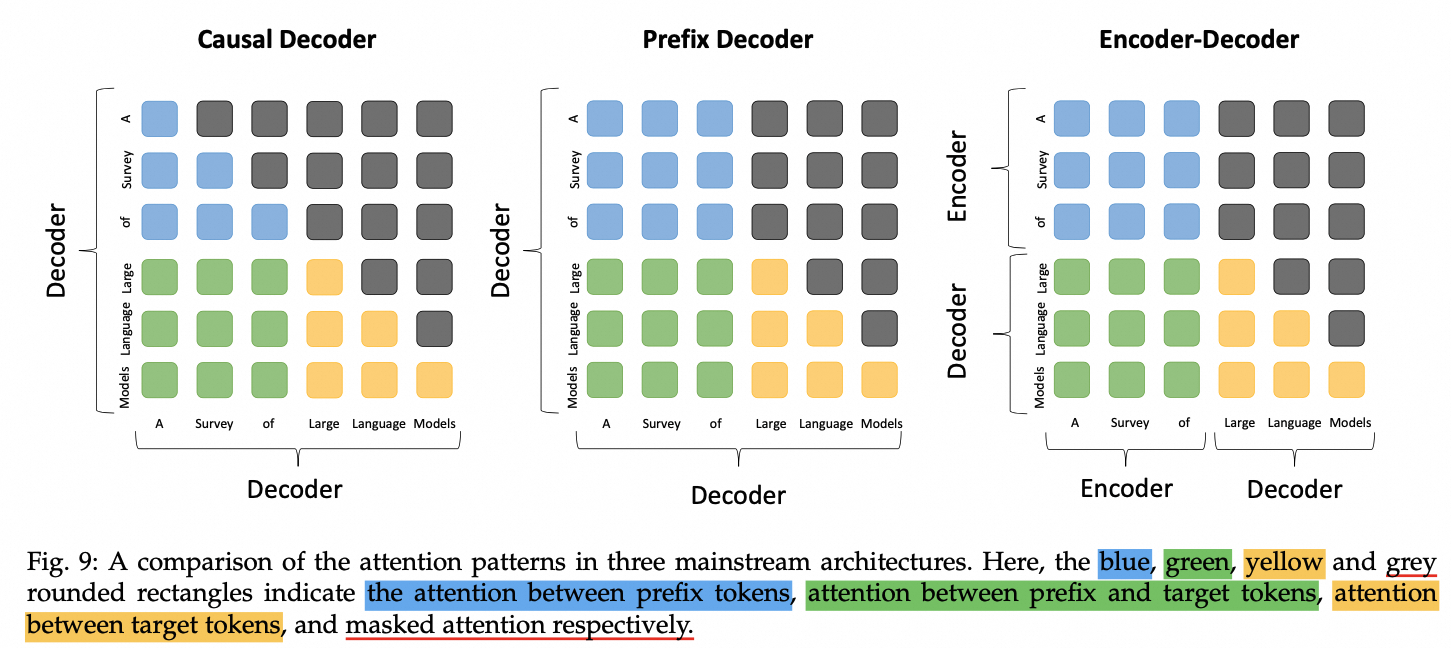
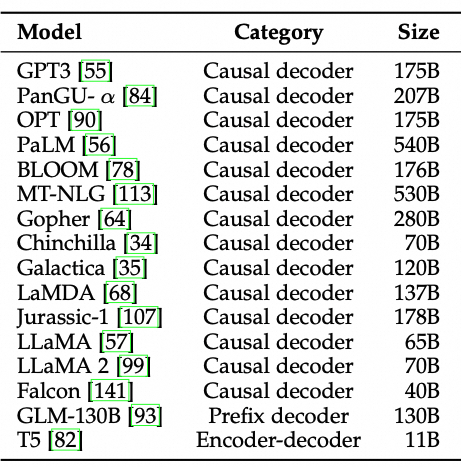
目前主流的LLM架构是Causal Decoder,目前还无法从理论上证明这种架构的优越性。
4. 参考文献
- Apertium: a free/open-source platform for rule-based machine translation
- An Introduction to Conditional Random Fields for Relational Learning
- Neural Machine Translation by Jointly Learning to Align and Translate.
- The Illustrated Transformer
- The Illustrated BERT, ELMo, and co.
- The Illustrated GPT-2
- 如何理解Transformer论文中的positional encoding
- Meta Learning:一种套娃算法
- Transformer的Score为什么Scale
- ChatGPT调研报告
- AIGC:从不存在到存在
- 清华大学通用预训练模型:GLM
- A Survey of Large Language Models
- Transition-Based Dependency Parsing with Stack Long Short-Term Memory
- Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
- Efficient Estimation of Word Representations in Vector Space
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Deep contextualized word representations
- Improving Language Understanding by Generative Pre-Training
- Language Models are Unsupervised Multitask Learners
- Language Models are Few-Shot Learners
- LLaMA: Open and Efficient Foundation Language Models
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
- GLM: General Language Model Pretraining with Autoregressive Blank Infilling
- All NLP Tasks Are Generation Tasks: A General Pretraining Framework
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer