1. 相关背景
1.1. 对话系统的定义
对话系统(Dialogue System,有时也称ChatBot)是人机交互技术(Human Computer Interaction, HCI)的核心领域,旨在最大限度地模仿人与人之间的对话方式,使得人类能够用更自然的方式和机器进行交流,帮助人类完成任务、获取信息、情感陪伴等。
从人机交互技术视角来看,对话机器人代表了一种新的交互范式。人机交互经历了三个阶段:
- 命令行界面(CLI,Command-Line Interface),通过文本命令让用户与计算机进行交互;
- 图形界面(GUI,Graphical User Interface),通过图形、文本、按钮、图标、颜色和动画等视觉元素来显示信息,让用户通过鼠标、触摸屏或其他输入设备与这些元素交互,操作计算机或移动设备;
- 对话界面(CUI,Conversational User Interface),通过对话进行人机交互,UI更加动态和智能
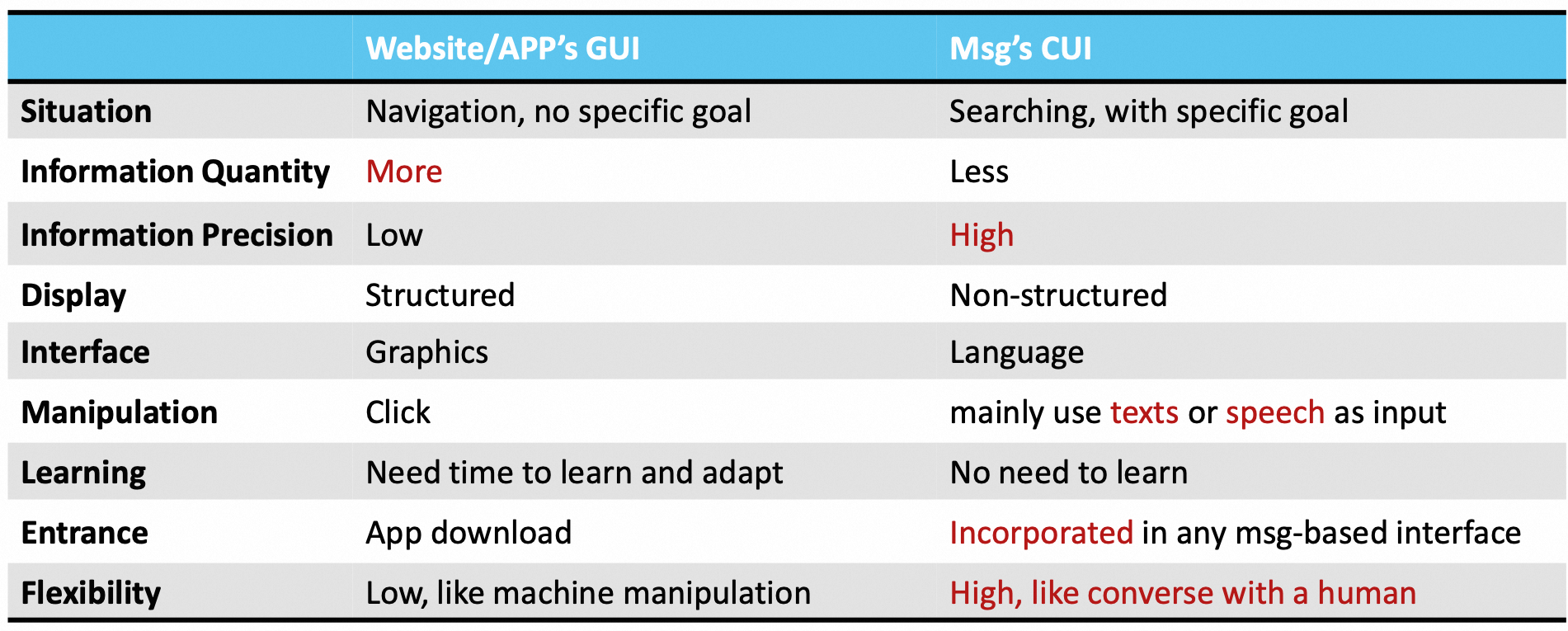
GUI和CUI的详细对比如下:
1.2. 对话系统类型
对话系统通常分为两类:任务型对话系统(task-oriented dialogue systems, TOD)和开放域对话系统(open-domain dialogue systems, ODD)。开放域对话系统也被称为非任务型对话系统(non-task-oriented dialogue system)、闲聊机器人(chit-chat bot)或者对话机器人(chat bot)。
任务型对话系统面向垂直领域,目的是使用尽 可能少的对话轮数帮助用户完成预定任务或动作, 例如预定机票、酒店和餐馆等。非任务型对话系统面向开放领域,要求其回复具有一致性、多样化和个性化。由于话题自由,因此 对系统的知识要求极高。

1.3. 对话系统发展阶段
从架构差异性上来看,对话系统目前有关三个重要阶段:
- 基于规则的对话系统。基于关键词模版配置的规则,代表工作有ELIZA:
- 基于机器学习/深度学习的对话系统。利用机器学习/深度学习大大降低了人力成本,对数据要求较高:
- 基于LLM Agent的对话系统。LLM具备知识、推理和生成能力,大大提高了对话质量上限:
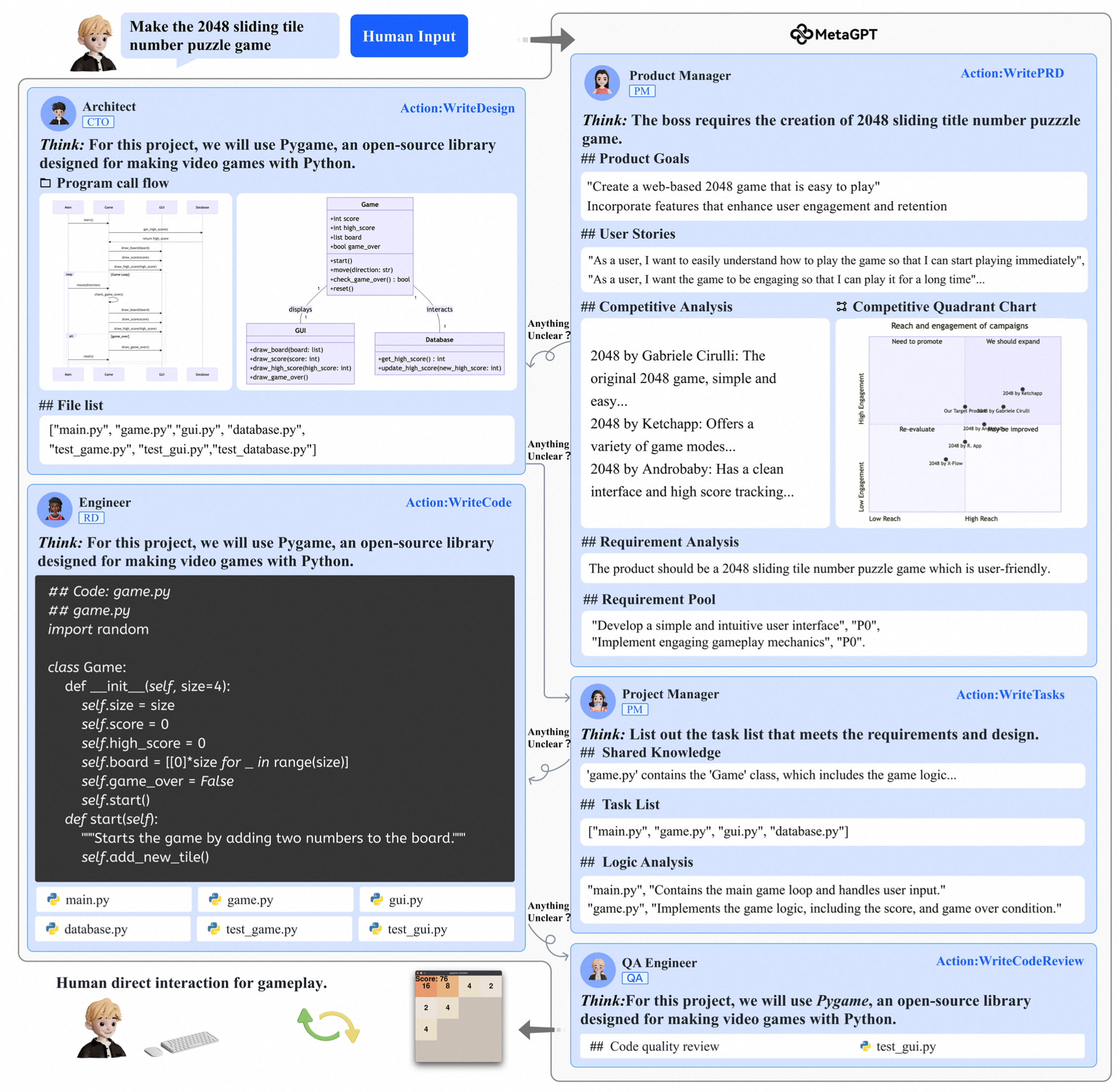
本篇调研主要讲解基于深度学习和基于LLM Agent的对话系统。
2. 基于深度学习的对话系统
2.1. 任务型对话系统
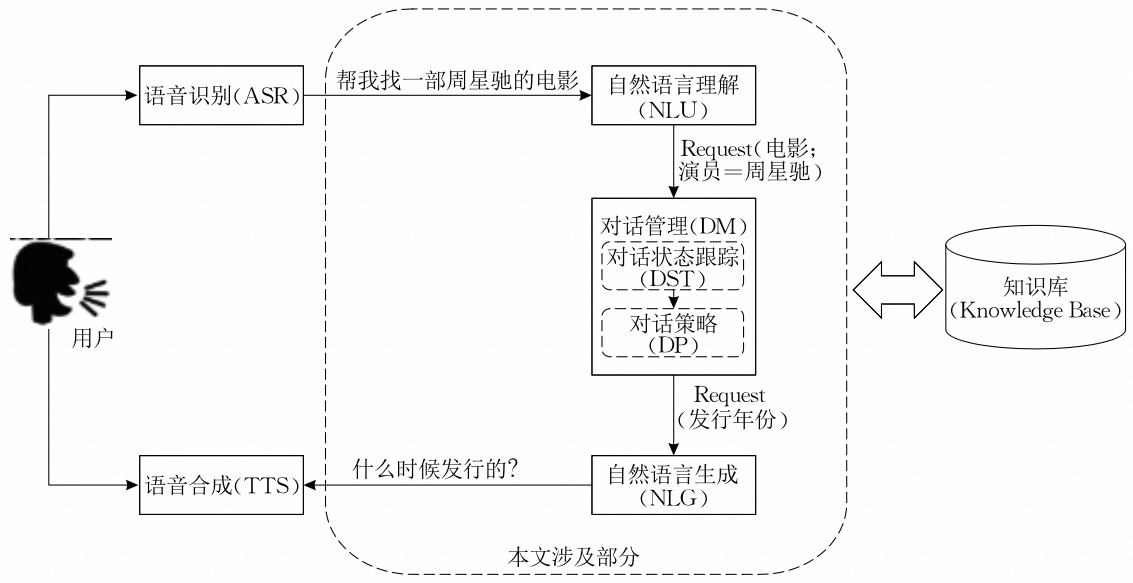
2.1.1. 整体架构
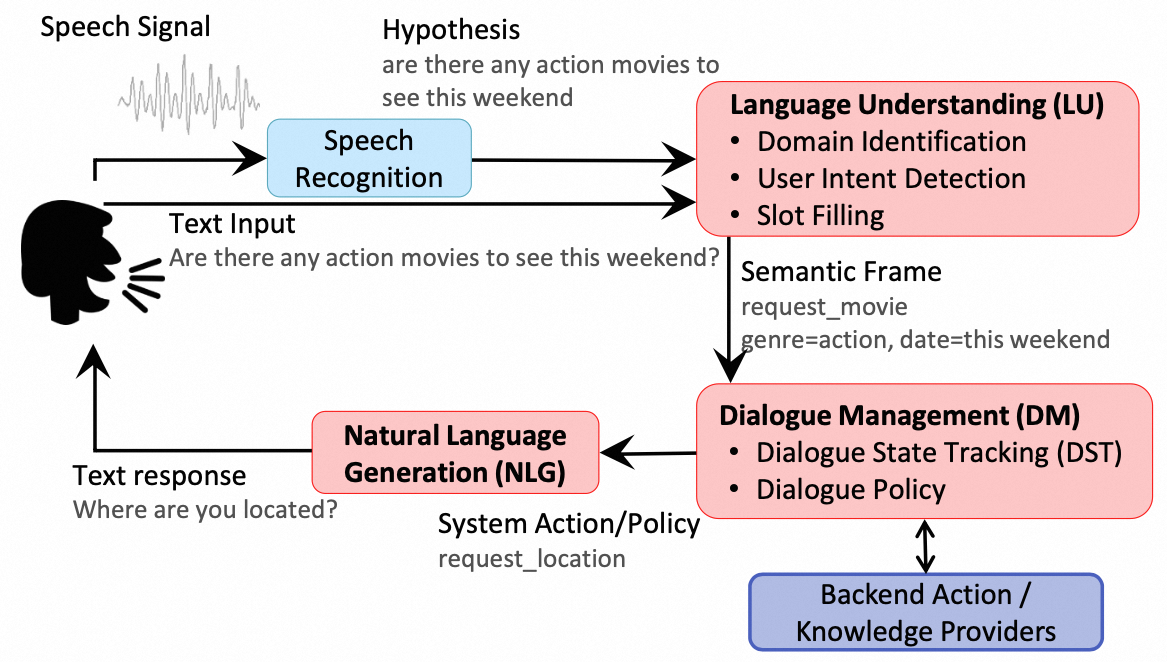
任务式对话系统一般包含SLU/NLU(Spoken/Natural Language Understanding)、DM(Dialogue Management)和NLG(Natural Language Generation)三个模块。其中DM又包含DST(Dialogue State Tracking)和DP(Dialogue Policy)两部分。简单来说,NLU模块负责理解用户当前对话的意图和关键信息用于后续决策,DM模块负责追踪用户当前的对话状态,并据此做出决策(例如追问、确认信息等),NLG模块负责根据上一步的决策信息生成回复。有些对话系统将NLU和DM联合建模,还有些对话系统直接端到端建模。
2.1.2. SLU/NLU模块
2.1.2.1. NLU任务定义
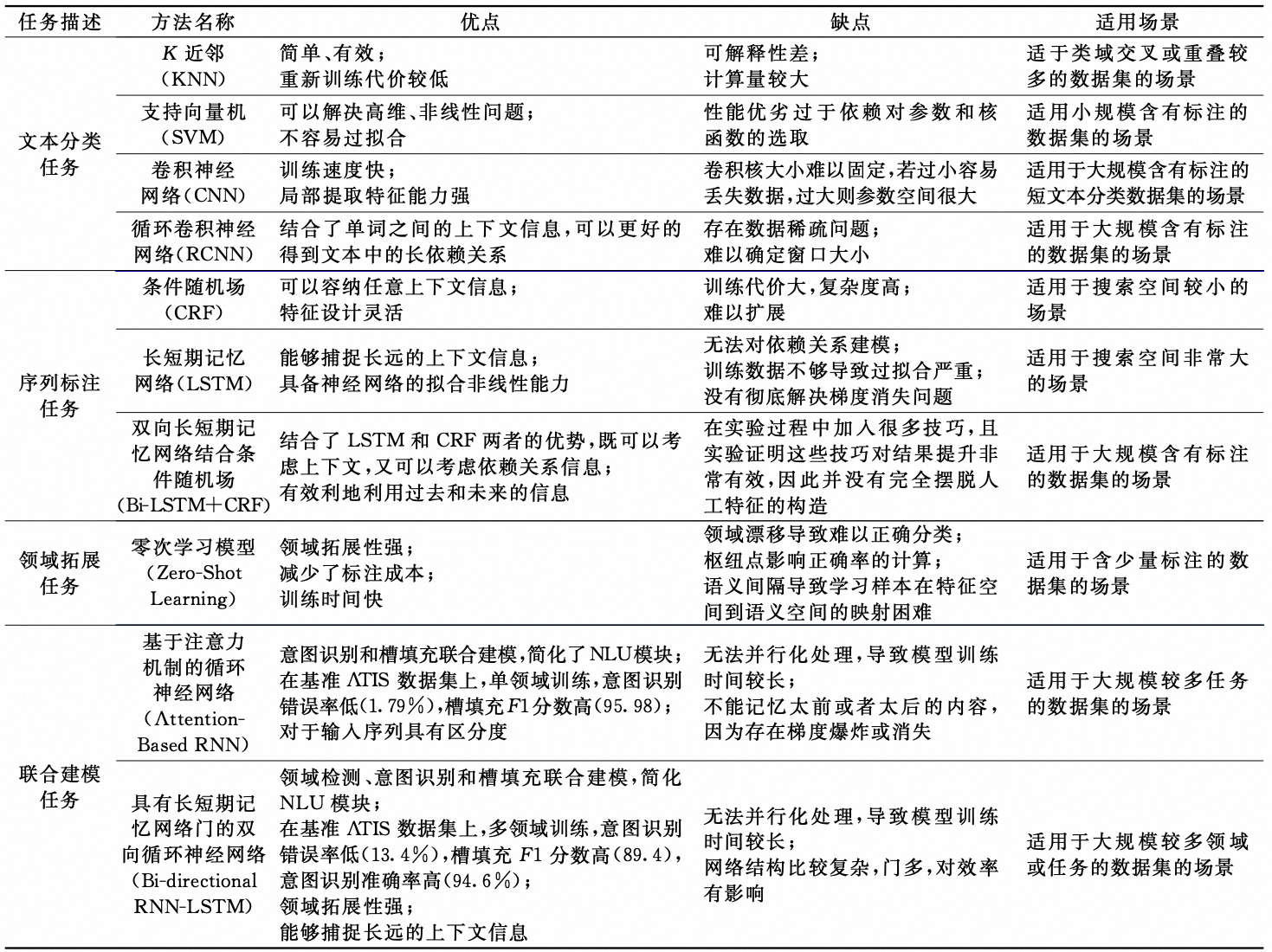
NLU包含三个任务:领域识别、意图识别和槽位识别。前两者为典型的分类任务,后者为典型的序列标注任务。

2.1.2.2. NLU方案
三个任务可单独建模,也可以联合建模。联合建模有两种范式:
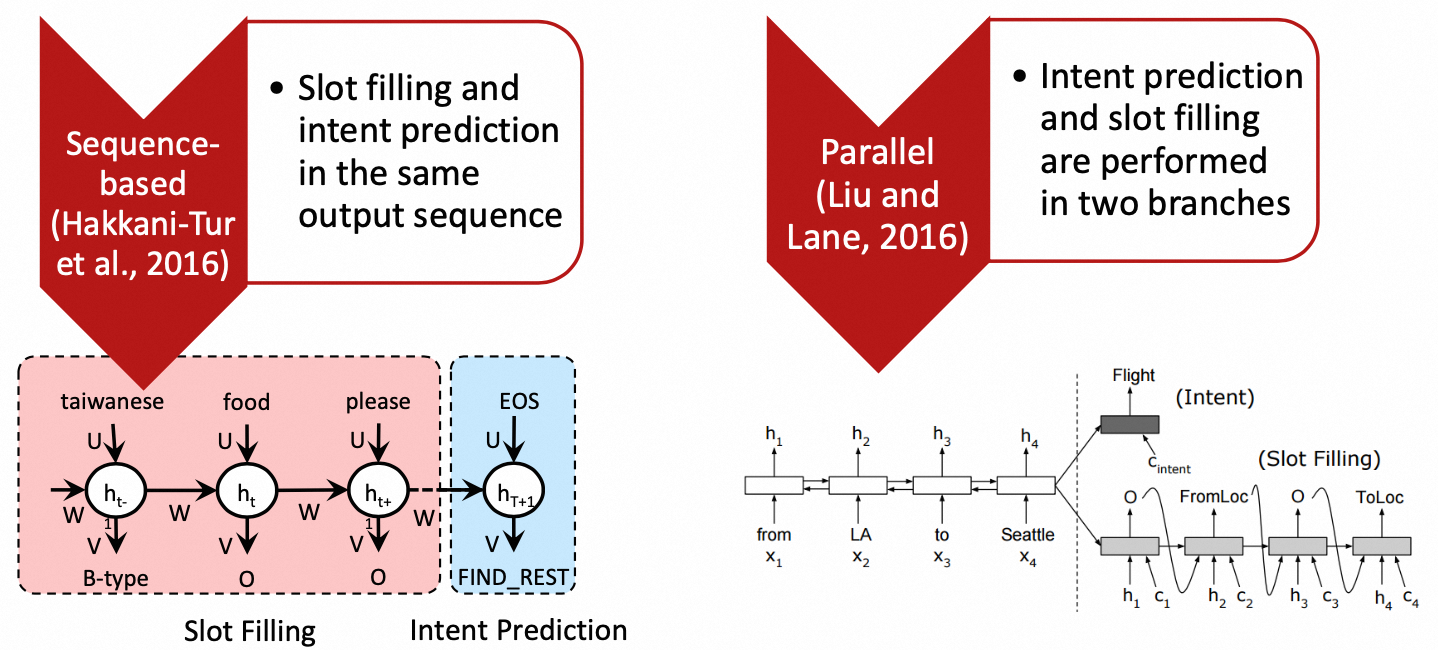
NLU代表性方法总结如下:
2.1.3. DST模块
2.1.3.1. 对话状态定义
对话状态(Dialogue State, DS)是一种将$t$时刻的对话表示为可供系统选择下一时刻动作信息的数据结构,可以看作每个槽值的取值分布情况。
首先看个简单的示例,快速理解下对话状态:
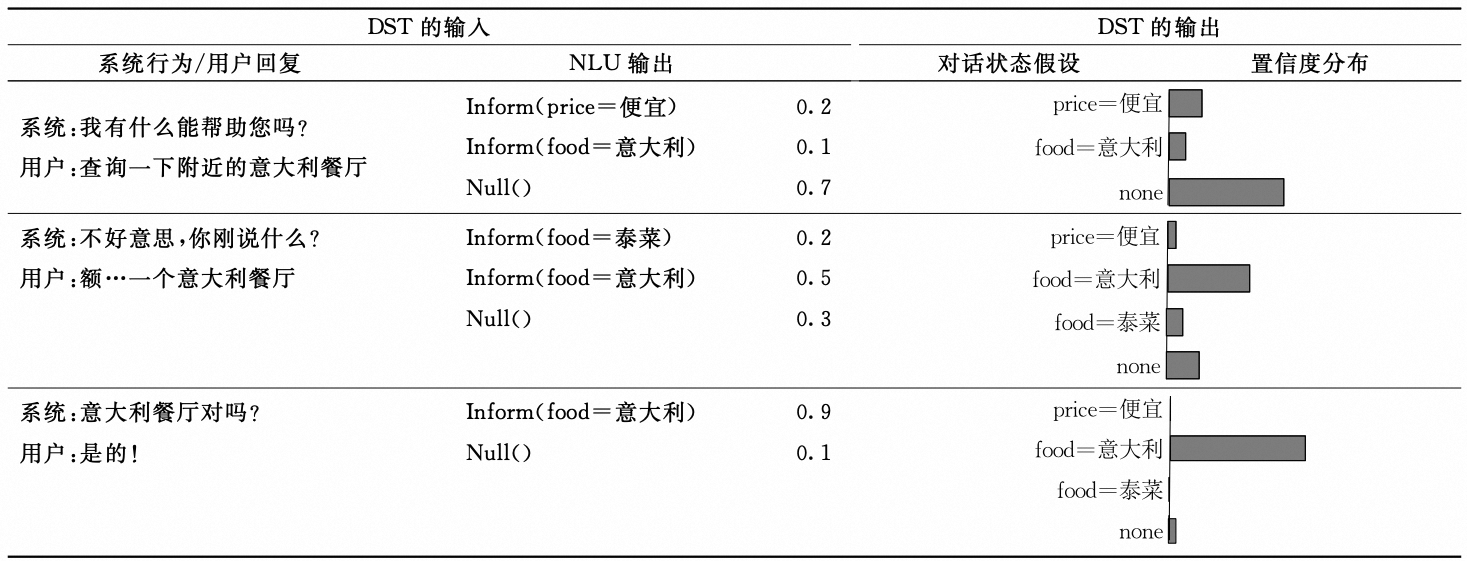
NLU和DST都会做槽位填充,不同的是NLU侧重从当前一轮对话提取槽值,而DST会考虑所有对话信息提取槽值。当然NLU和DST可以联合建模。一个完整的对话状态包含三部分:
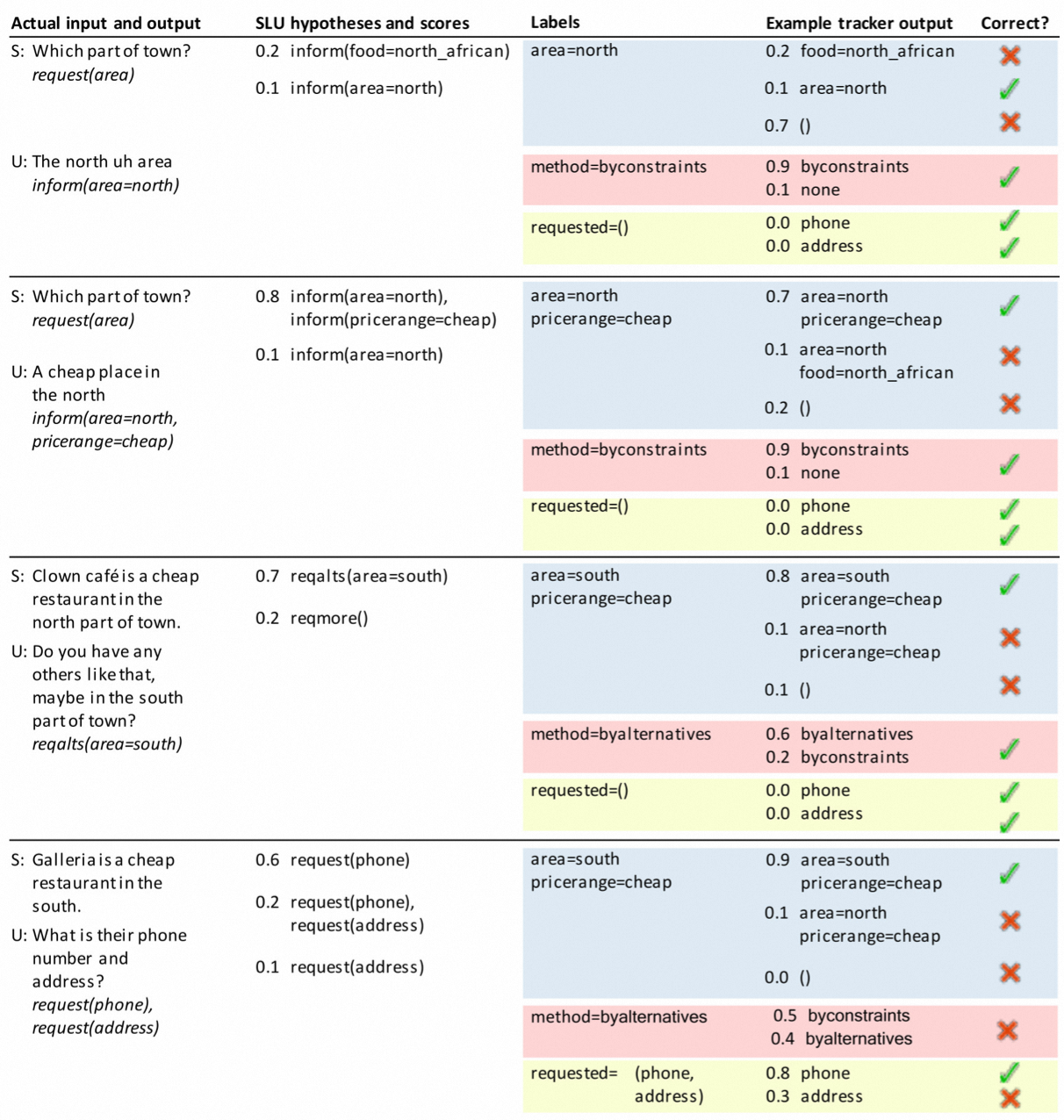
- 目标约束有关的槽位. 约束的值来自用户对话或者一些特殊值。特殊值一般包含$Dontcare$和$None$,前者表示该槽位用户不关心,后者表示用户还未指定该槽位的值。
- 请求槽位. 它可以是用户查询以从代理处获得答案的槽位名称列表。
- 当前轮次的请求方法. 它由指示交互类别的值组成。$byconstraints$表示用户试图在他的要求中指定约束信息;$byalternatives$表示用户需要一个替代实体;$finished$表明用户打算结束对话。
具体的例子如下:
2.1.3.2. DST方案
DST以当前的动作$u_n$、前$n-1$轮的对话状态和相应的系统动作作为输入,输出其对当前对话状态$s_t$的估计。经典的DST模型为NBT(Neural Belief Tracker),将槽值抽取变为二分类模型,大大降低了任务难度。
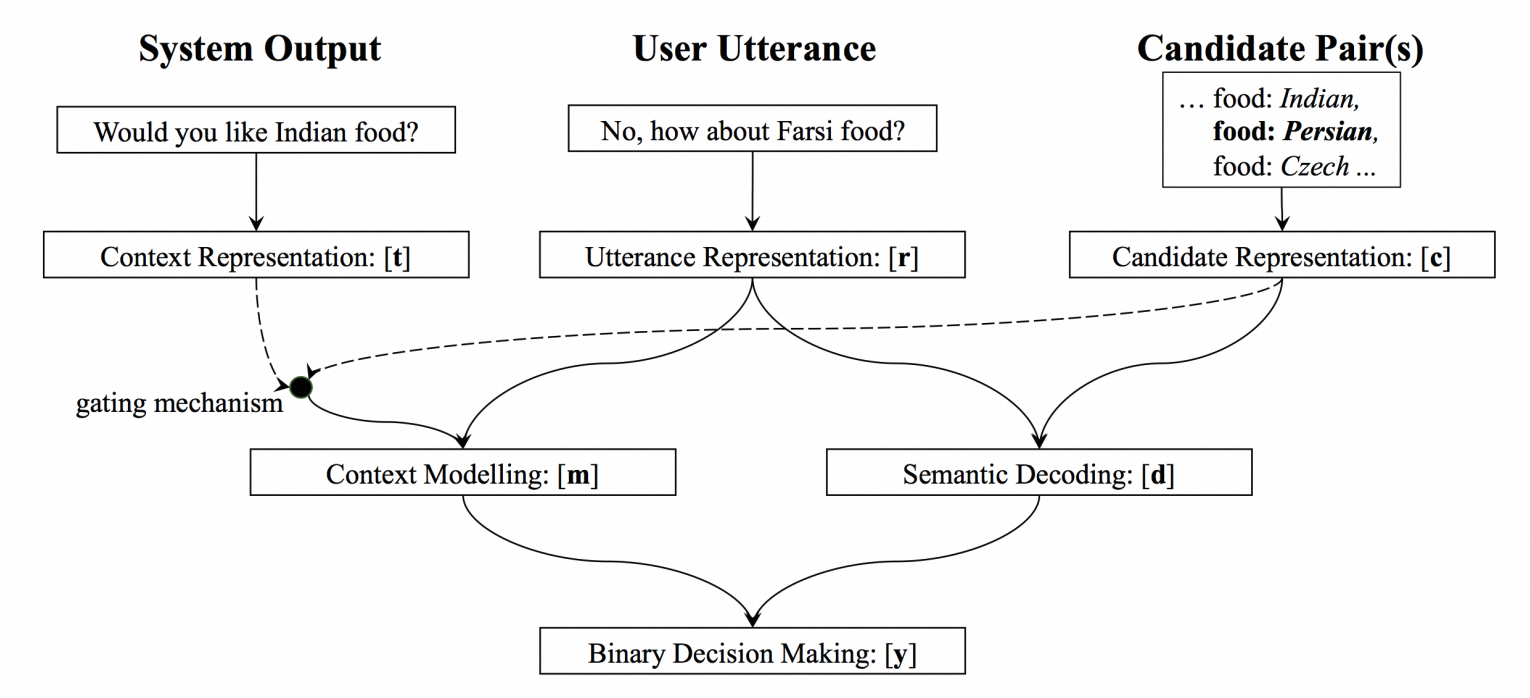
其他DST方法总结如下:
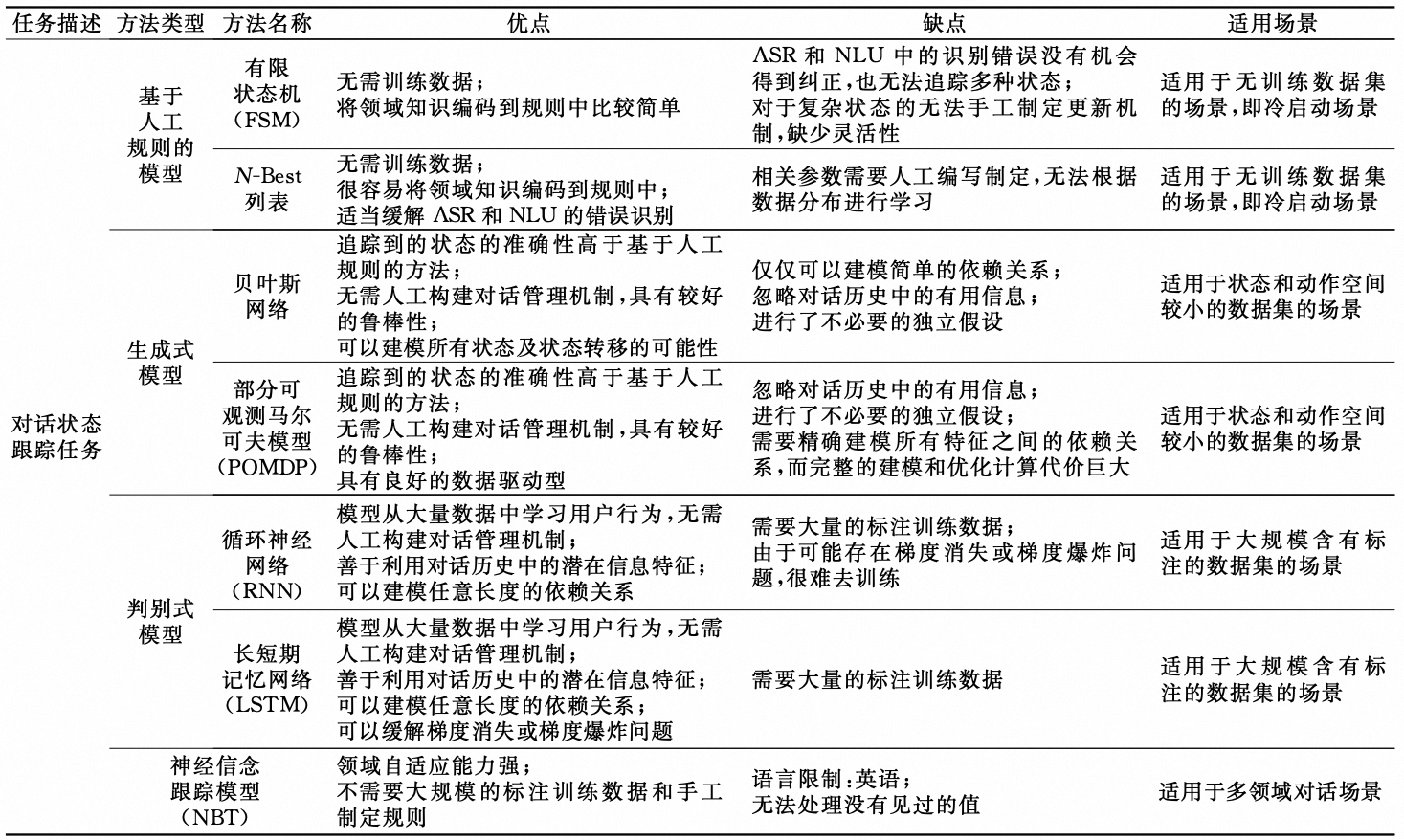
2.1.4. DP模块
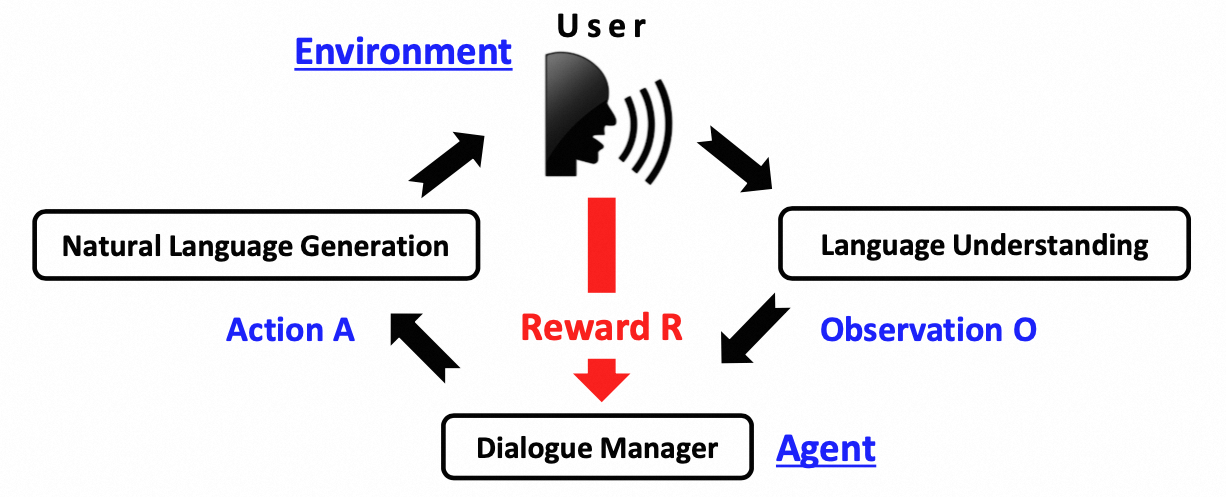
2.1.4.1. DP问题定义
对话策略根据DST估计的对话状态$s_t$,通过预设的候选动作集,选择系统动作或策略$a_n$。动作可以是查询数据库、询问用户等。DP性能的优劣决定着人机对话系统的成败。DP模型可以通过监督学习、强化学习和模仿学习得到。
监督学习需要专家手工设计对话策略规则,通过上一步生成的动作进行监督学习。由于DP的性能受特定域的特性、语音识别的鲁棒性、任务的复杂程度等影响,因此手工设计对话策略规则比较困难, 而且难以拓展到其他领域。这使得强化学习逐渐代 替专家手工设计一系列复杂的决策规则。另外从任务定义上看,强化学习擅长解决序列决策问题。
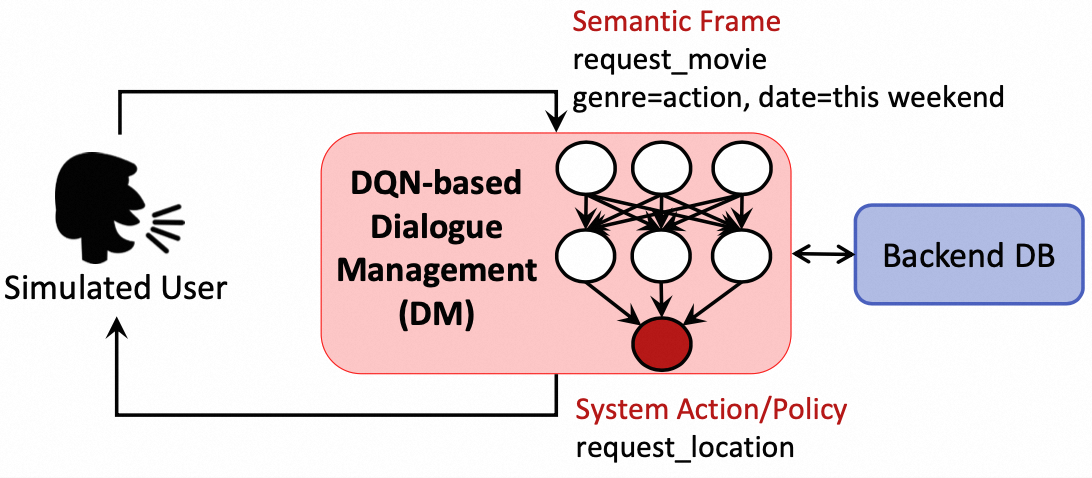
2.1.4.2. DP方案
下面是一个通过DQN建模DP的方案,输入为观测到的对话语义信息和数据库,输出为系统动作。
DP方法总结如下:

2.1.5. NLG模块
2.1.5.1. NLG任务定义
NLG的主要任务是将DM模块输出的抽象表达转换为句法合法、语义准确的自然语言句子。一个好的应答语句应该具有上下文的连贯性、回复内容的准确性、可读性和多样性。广义的NLG还包含生成GUI,给定可选的交互对话动作。

2.1.5.2. NLG方案
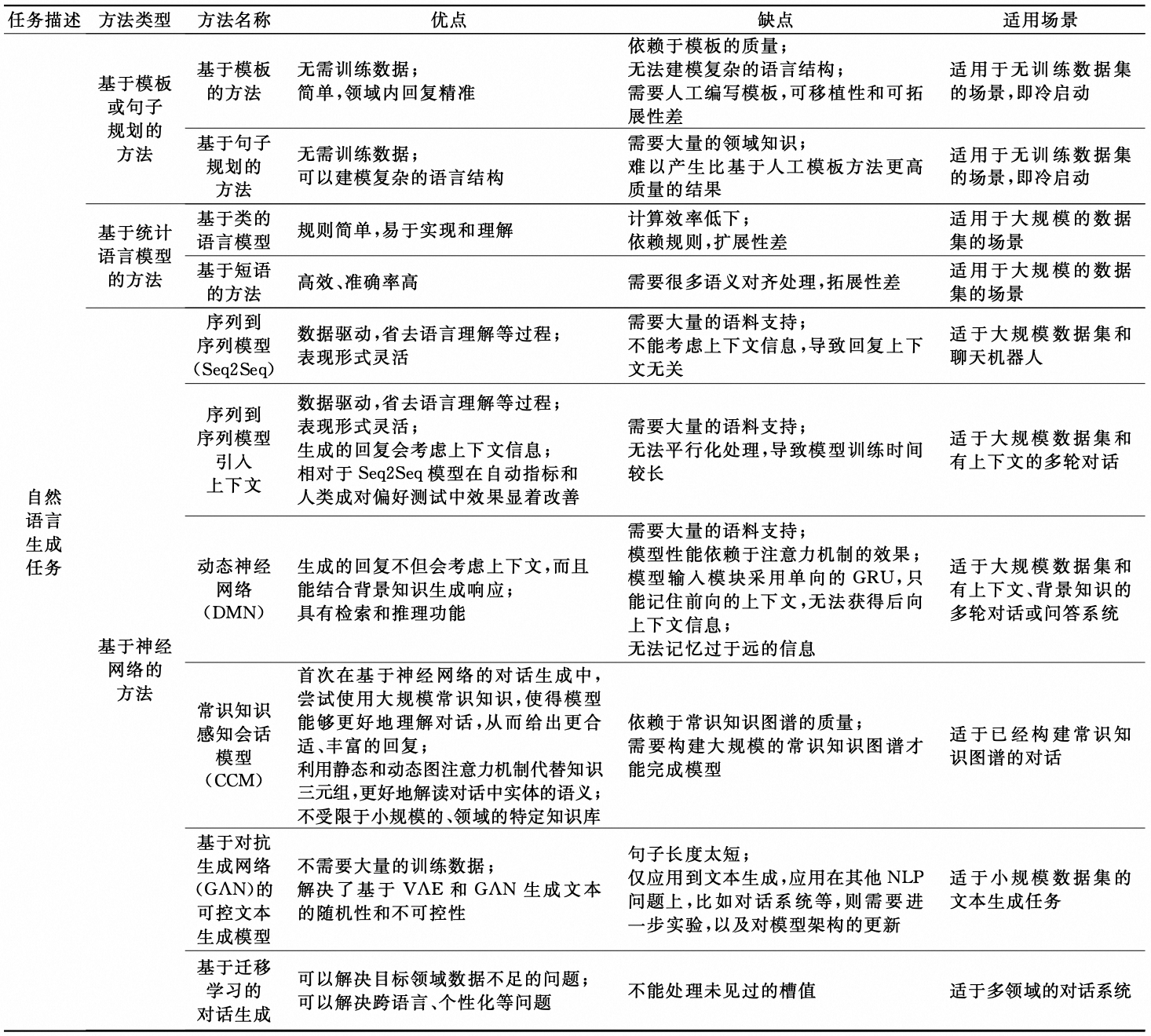
NLG的方法可以划分为:基于规则模板/句子规划的方法、基于语言模型的方法和基于深度学习的方法。
基于规则的方法示例如下:

基于深度学习的示例如下:
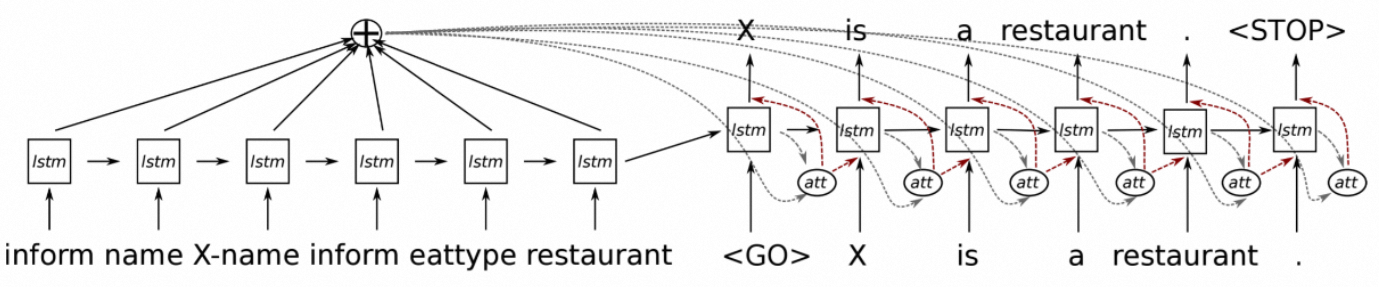
NLG的方法汇总如下:
2.1.6. 端到端的任务式对话系统
2.1.6.1. Pipeline方法缺点
Pipeline方法一般分别建立NLU、DM和NLG等模块,这些子模块通常还要分解为更小的子任务分别建模,然后按照顺序将这些模块连接起来。这种方法简单清楚,各个模块任务明确,并且可以分开研究,各自解决各自的问题。
但是Pipeline方法的问题也很明显:
- 领域相关性强。针对每个领域都需要人工设计语义槽、动作空间和决策,导致系统的设计和领域非常相关,难以扩展到新的领域。
- 模块之间独立。各个模块之间相互独立,需要为每个模块提供大量的领域相关的标注数据。
- 模块处理相互依赖。上游模块的错误会级联到下游模块,下游模块的反馈难以传到上游模块,使其很难识别错误来源。例如DM的决策出现错误,其原因可能是语言理解发生了错误,也可能是语音识别的错误。并且,由于一个模块的输入依赖于另一个模块的输出,当将一个模块调整到新环境或更新数据,其他所有模块为保证全局最优要进行相对调整。语义槽和特征也可能发生相应改变,而这个过程需要耗费大量的人力。
2.1.6.2. 端到端方法
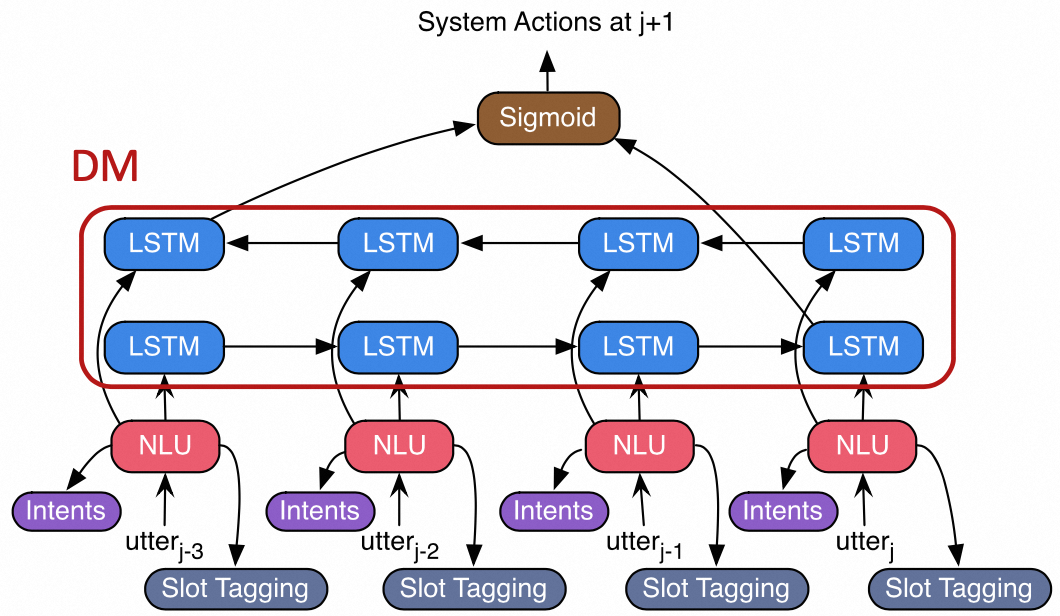
NLU和DM的端到端建模示例:DM建模成隐藏状态,将NLU任务和DM任务联合训练,对两个任务都有提升。
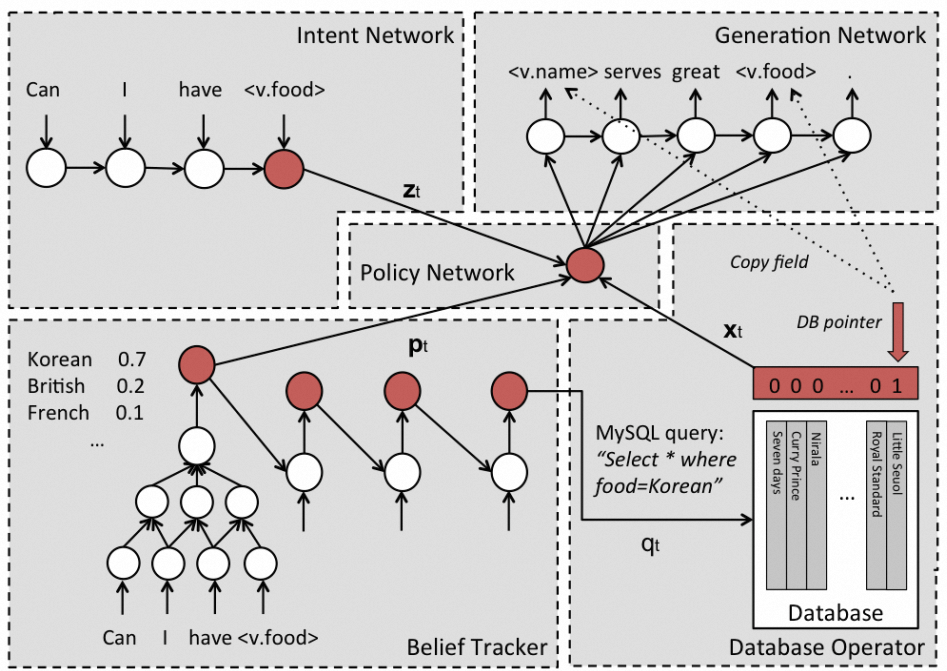
整个对话系统端到端建模示例:
端到端方法汇总如下:

2.1.7. 对话系统评估
任务式对话整体衡量可以用任务达成率和对话轮次指标,达成率越高越好,用的对话轮次越小越好。每个模块的评估方法如下:

2.2. 开放域对话系统
开放域对话系统旨在与用户进行无特定任务和领域限制的闲聊(Ritter等人,2011),通常是完全数据驱动的。开放域对话系统大致可以分为三类:生成式系统(generative systems)、检索式系统(retrieval-based systems)和集成式系统(ensemble systems)。
生成式系统应用sequence-to-sequence模型,将用户信息和对话历史映射为可能未出现在训练语料库中的响应序列。相比之下,检索式系统尝试从某个确定的响应集中找到一个预先存在的响应。集成式系统结合了生成方法和检索方法,有两种方式:可以将检索到的响应与生成的响应相比较,从中选择最佳者;生成模型也可以用来优化检索到的响应。
生成式系统能够产生灵活的、与对话上下文相关的响应,但有时它们缺乏连贯性,倾向于生成单调的响应。检索式系统从人类响应集中选取响应,因此能够在表面水平的语言上实现更好的连贯性。然而,检索系统受限于响应集的有限性,有时检索到的响应与对话上下文的相关性较弱。
3. 基于LLM的对话系统
3.1. 基于DL的TOD难点
基于深度学习的任务式对话系统有以下几个发展方向:
- 低资源启动。任务型对话系统的成果往往依赖于大量高质量的语料作为训练数据,然而对话数据通常是异构的。例如聊天数据很多,但面向任务的对话数据集非常小。特定领域的对话数据的收集和标注是需要耗费大量的人力。
- 域适应能力。如何以更低的开发成本覆盖更多的领域和场景是任务型对话系统的关键问题之一,快速更新对话 智能体以处理不断变化的环境非常重要。目前的任务型对话系统针对每一个领域都需要手工制定模板导致领域拓展性不足。
- 领域知识和常识的引入。在深度学习框架中融合语言理解能力和推理能力的重要方法是引入领域知识和常识,因为真实人与人之间的交互需要相关领域的知识储备,仅仅依靠对话文本包含的信息无法准确地理解用户输入和恰当地回复用户。而在实际对话中,还需要对信息进行推理并回答,常识知识的引入可以使得对话系统对于用户的话语更深入的理解,从而更贴近真实人类和谐、自然的交互方式。
以下面的多领域DST为例,需要常识和推理才能正确识别槽位。

而大模型具有知识、推理、生成的能力,并且启动资源低,不需要标注大量对话数据,天然适合建模对话式任务。
3.2. 基于LLM增强的对话系统
3.2.1. 整体架构
该架构主要在传统搜推架构的基础上,使用LLM增强其中关键模块。
3.2.2. NLU模块
3.2.2.1. 直接使用LLM
意图类别较少时,可以直接使用大模型做意图识别等NLU相关任务。
3.2.2.2. LLM+传统模型
当意图类别较多时,可以先使用传统模型召回少量意图,再使用LLM判断最匹配的意图。
3.2.2.3. LLM蒸馏传统模型
3.2.3. NLG模块
3.2.3.1. 利用LLM构造FAQ知识库
离线利用LLM构造FAQ知识库,在线通过Q2Q召回QA Pair,将Answer作为结果直接返回给用户
3.3. 基于LLM Agent的对话系统
3.3.1. 整体架构
3.3.2. Agent模块
类似autoGPT,通过self-ask和react控制对话流程,显式的对话收敛干预机制
3.3.3. RAG模块
3.3.3.1. KV检索
构造结构化知识库,通过KV检索相关知识
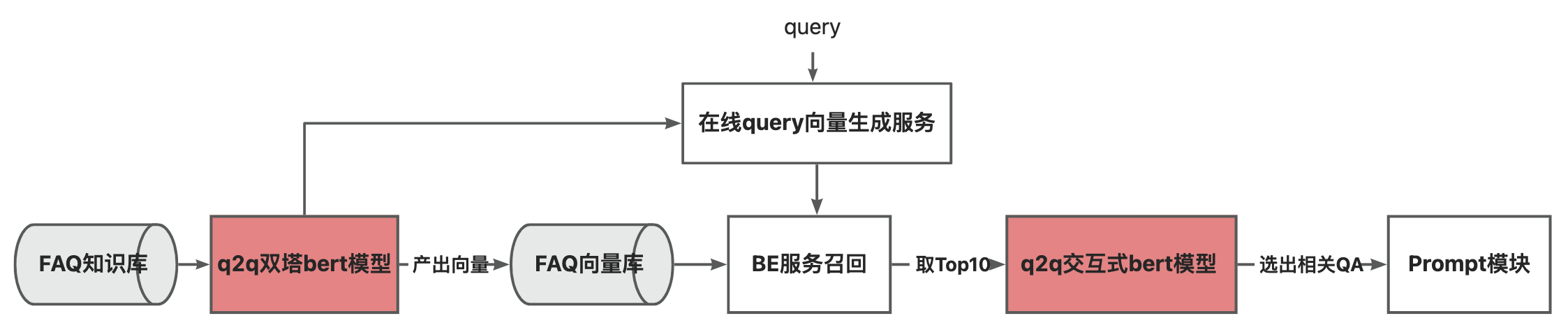
3.3.3.2. Q2Q检索
对结果的正确性有较高要求的知识,需要先离线构造FAQ知识库,在线时计算Query和Query的相似度,选择相似度最高的QA Pair,将Answer作为知识输入到LLM
3.3.3.3. Q2A检索
泛主题、长文本知识(影视剧情、商品详情)可以先划分为多个chunks,在线计算Query和chunk的相似度检索知识
4. 参考文献
- Recent Advances in Deep Learning Based Dialogue Systems: A Systematic Survey
- Deep Learning for Dialogue Systems
- 任务型对话系统研究综述
- 阿里小蜜技术实践-海青
- An End-to-End Trainable Neural Network Model with Belief Tracking for Task-Oriented Dialog
- ELIZA – A Computer Program For the Study of Natural Language Communication Between Man And Machine
- Neural Belief Tracker: Data-Driven Dialogue State Tracking
- End-to-End Joint Learning of Natural Language Understanding and Dialogue Manager
- A Network-based End-to-End Trainable Task-oriented Dialogue System