1. 背景
春节期间,DeepSeek爆火出圈,性能在开源和闭源模型中达到顶尖水平,同时显著降低了训练和推断成本,并在推理领域取得重大突破,被誉为开源领域的"ChatGPT时刻"。R1模型是DeepSeek一年来持续探索与积累的成果,体现了算法、架构与硬件的协同设计。本文将重点解析R1模型的核心算法,并简要介绍其基础设施。
2. 性能与成本
2.1. 评估数据集
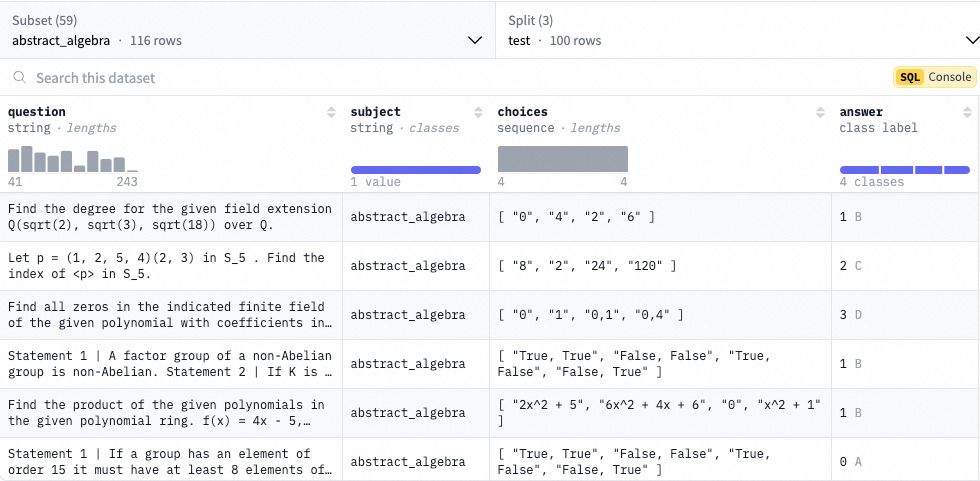
- MMLU(Massive Multitask Language Understanding):[Paper] [Dataset Card]
这是一项大规模的多任务测试,包含来自不同知识领域的选择题。测试涵盖人文学科、社会科学、自然科学以及其他一些对某些人来说重要的学习领域。这包括57个任务,如基础数学、美国历史、计算机科学、法律等。要想在这一测试中取得高准确率,模型必须具备广泛的世界知识和强大的问题解决能力。
- MMLU-Pro:
MMLU-Pro数据集是一个更加稳健且富有挑战性的大规模多任务理解数据集,旨在更严格地评估大型语言模型的能力。该数据集涵盖了多个学科的12,000道复杂问题。主要有三项改进:首先,将选项数量从4个增加至10个,提升了评估的真实性和挑战性,显著降低了随机猜测的得分;其次,提高了问题难度,增加更多推理型问题,使得CoT的结果可能比PPL高出20%;最后,通过增加干扰项,降低随机猜测概率,增强了基准测试的鲁棒性,模型得分对提示变化的敏感性从4-5%降至2%。
- GPQA:[Paper] [Dataset Card]
GPQA包含了448道由生物学、物理学和化学领域的专家编写的多项选择题。我们确保这些问题的质量高且极具难度:在相应领域拥有或正在攻读博士学位的专家答题准确率为65%(在排除专家事后发现的明显错误后,准确率上升至74%),而技能高超的非专家验证者尽管平均花费超过30分钟并拥有无限制的网络访问权限(即问题"防谷歌"),准确率仅为34%。这些问题对于最先进的AI系统同样困难,我们基于GPT-4的最强基线模型准确率仅为39%。
- MATH 500:[Paper] [Dataset Card]
这个数据集包含了来自OpenAI在其论文《Let’s Verify Step by Step》中创建的MATH基准测试的500道题目子集。

- AIME 2024:[Dataset Card]
该数据集包含了2024年AIME I和AIME II测试中的30道题目。
- Codeforces:[Source]
编程试题。
- SWE-bench:[Dataset Card]
SWE-bench 是一个用于测试系统自动解决 GitHub 问题能力的数据集。该数据集收集了来自 12 个热门 Python 仓库的 2,294 个"问题-拉取请求"对。评估通过单元测试验证进行,并以拉取请求后的行为作为参考解决方案。
2.2. 评估结果
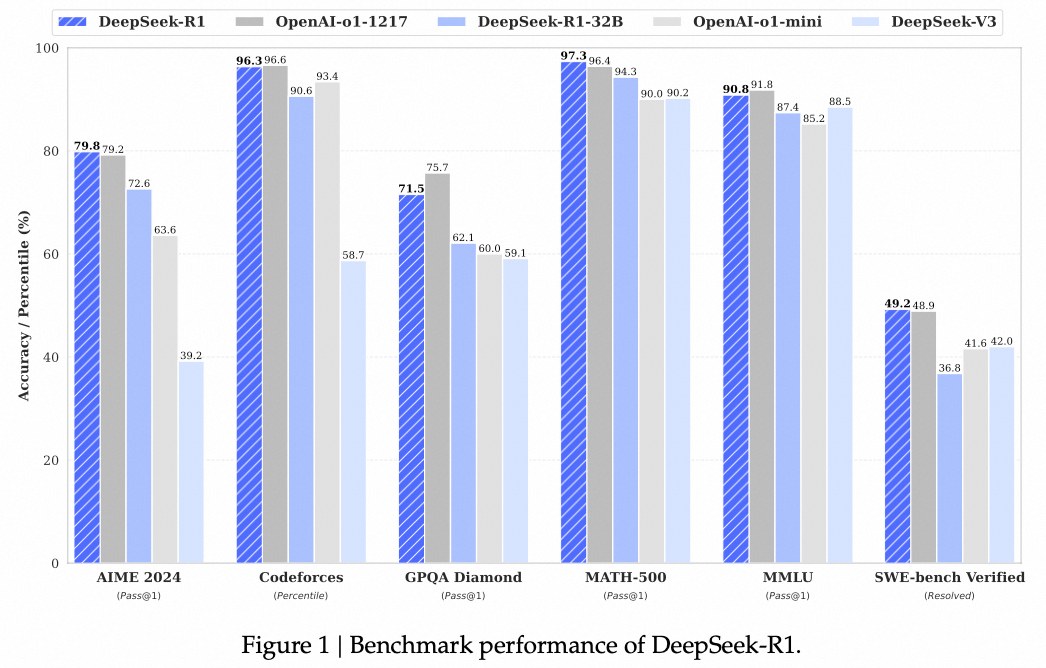
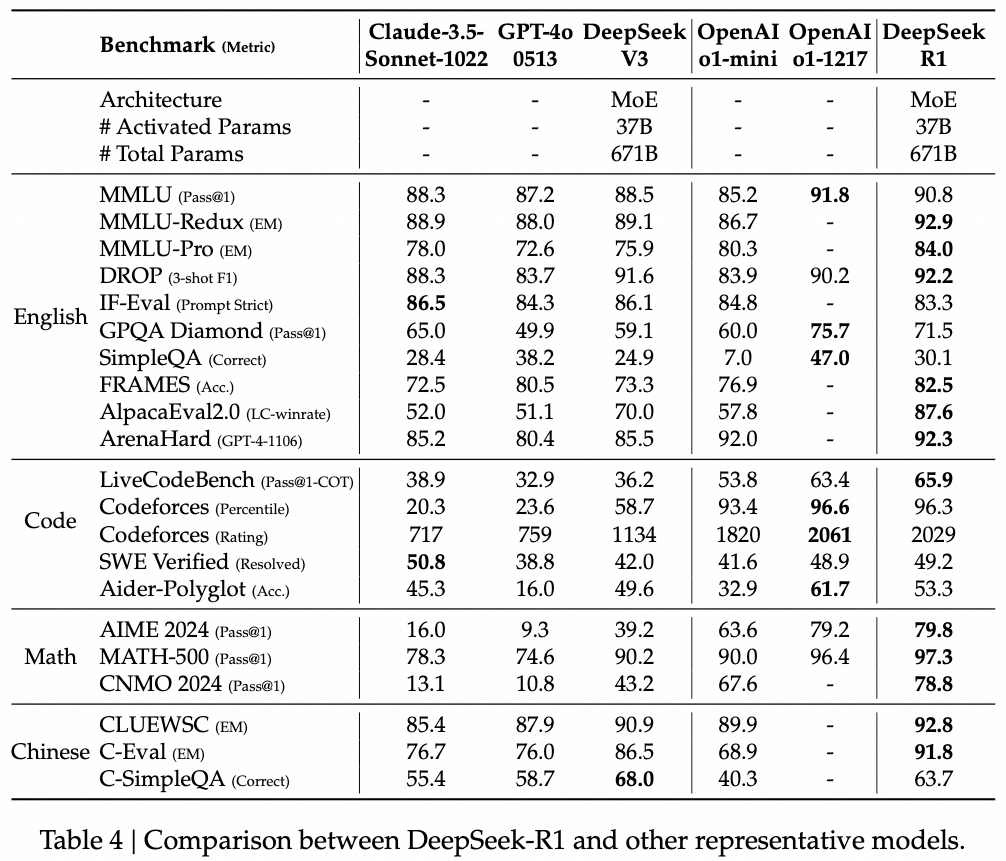
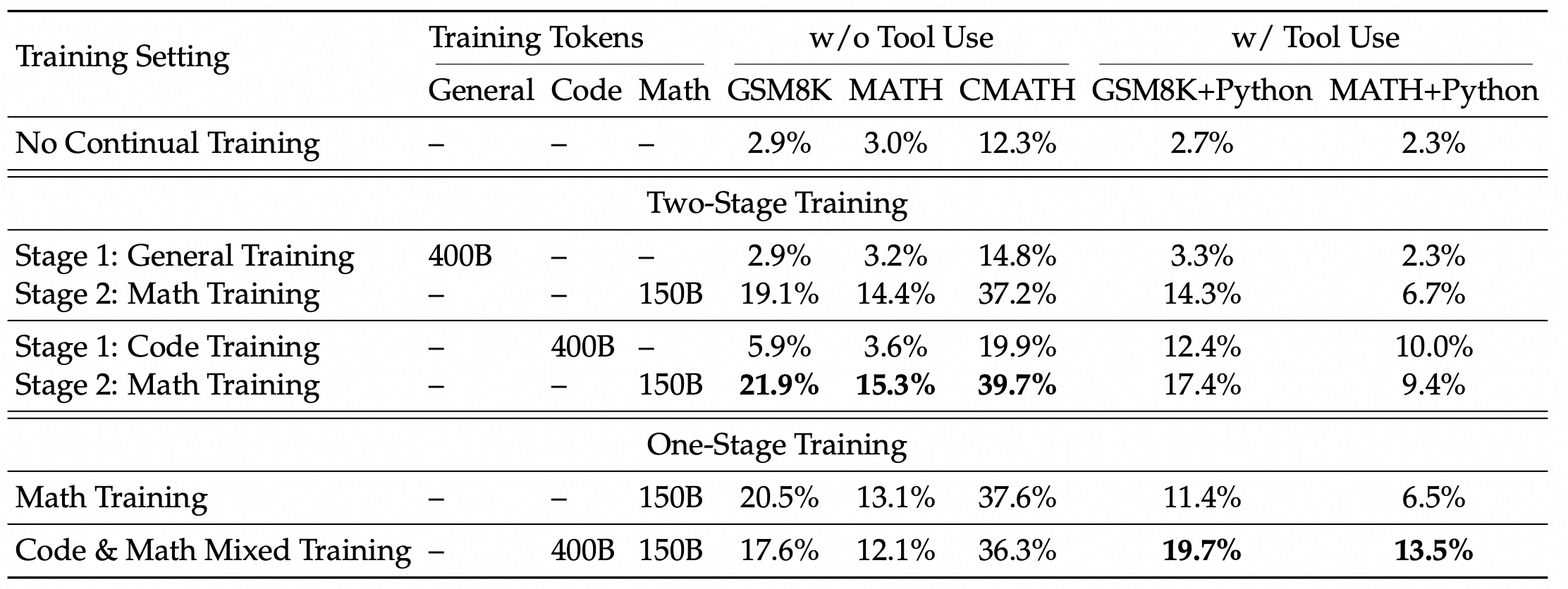
2.3. 训练与推理成本
训练成本:Llama3-405B使用了30.8M GPU时,而DeepSeek-V3 性能更强,仅使用了2.8M GPU时(计算量减少了约 11 倍)。

Chat类模型推断价格对比:
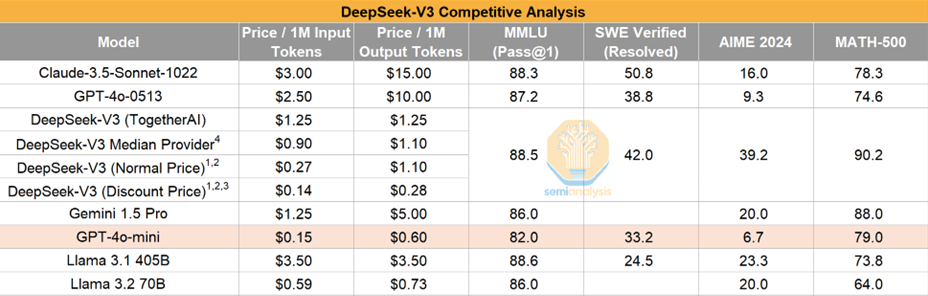
Reasoner类模型推断价格对比:
| input (Price/1M) | Cached input (Price/1M) | Output (Price/1M) | |
|---|---|---|---|
| OpenAI o1 | $15.0 | $7.5 | $60.0 |
| OpenAI o3-mini | $1.1 | $0.55 | $4.4 |
| DeepSeek R1 | $0.55 | $0.14 | $2.19 |
3. 模型架构
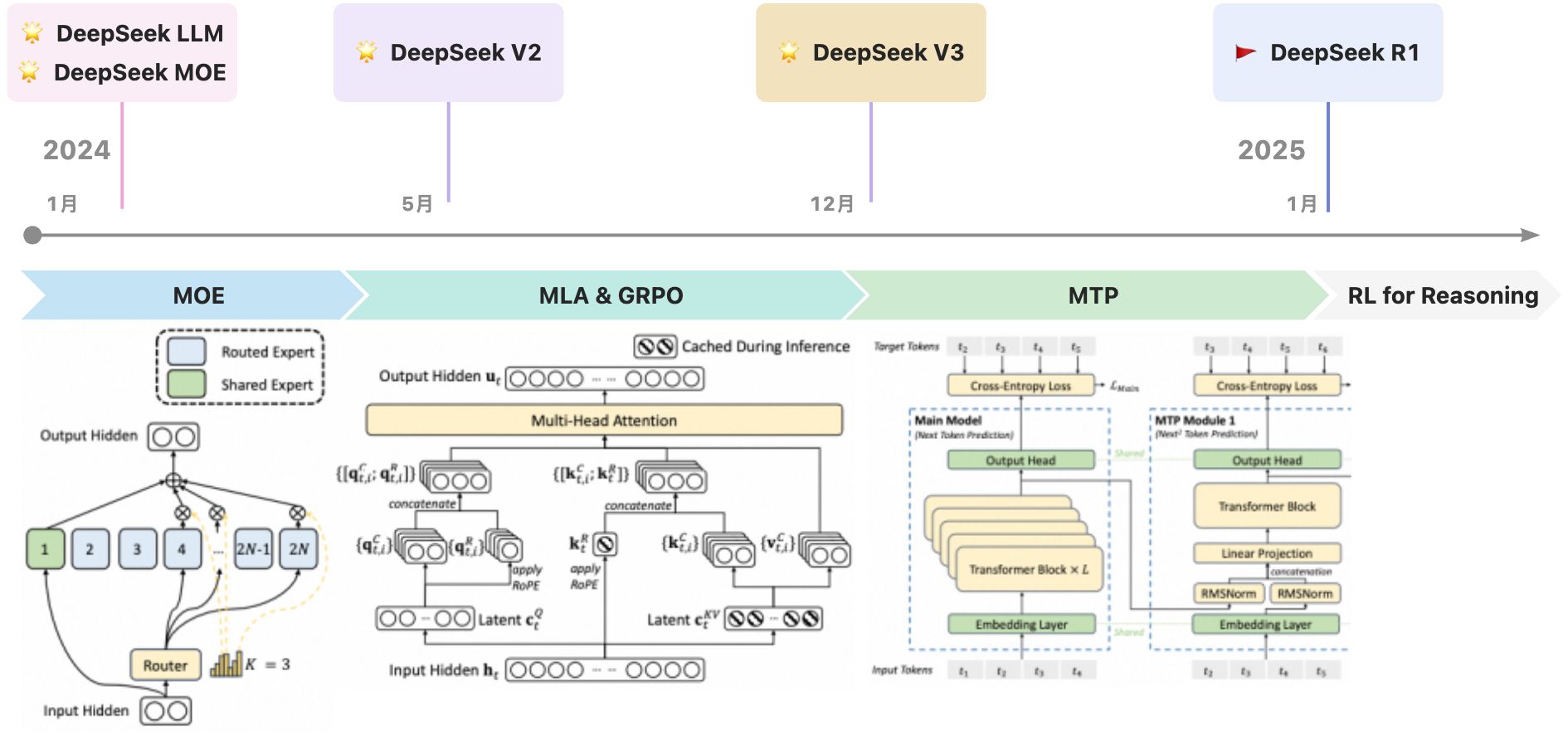
DeepSeek主打的卖点是计算开销低,从架构上主要通过MLA和MOE两个模块实现。
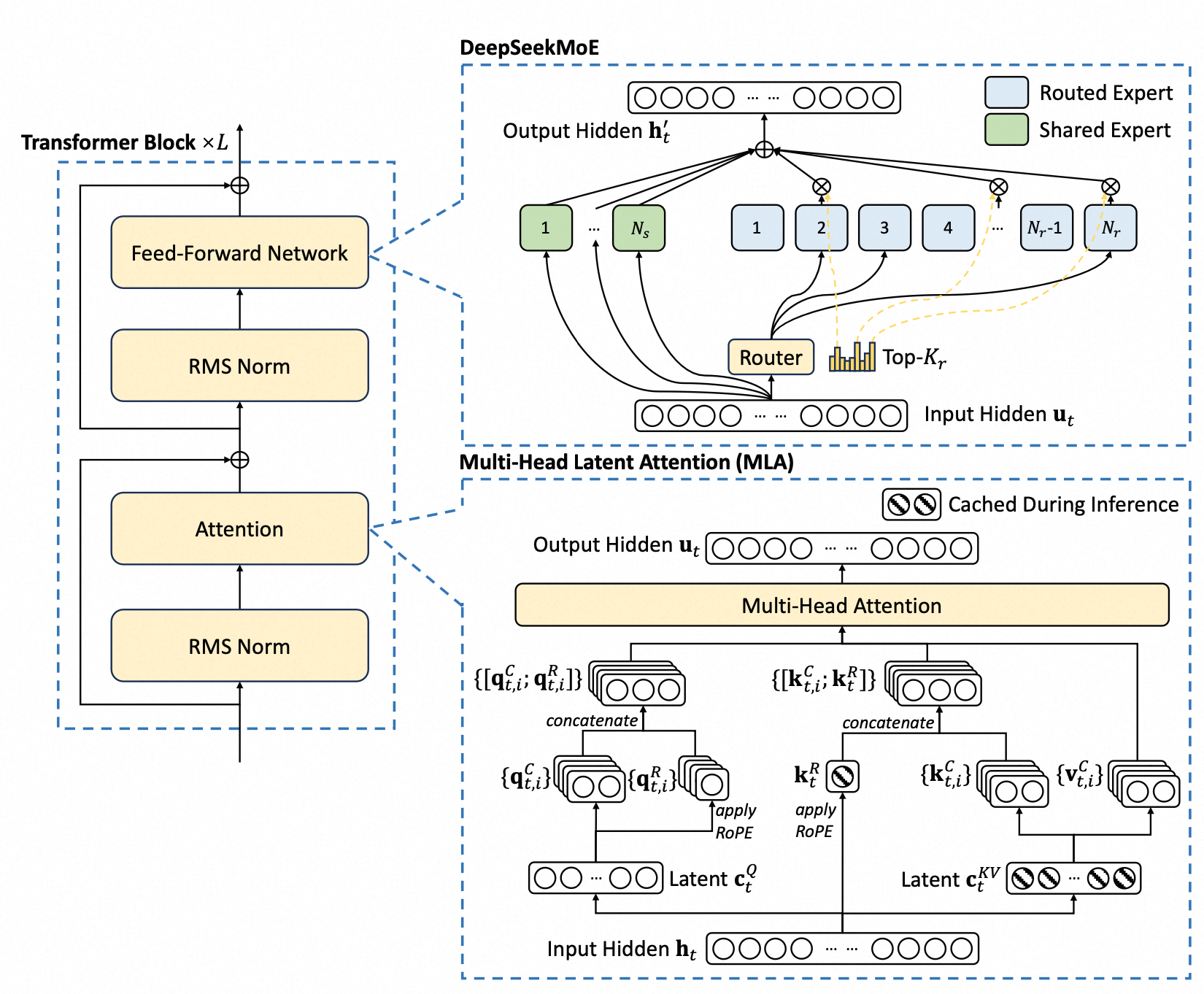
3.1. MOE
MOE(Mixture of Expert)自Google提出以来便应用到多个领域,包括NLP、多模态、视觉和推荐系统中。大语言模型参数量与性能有密切关系,但参数量增大也会带来训练和推断成本的上升。MOE是一种在扩大模型参数时管理计算成本的非常有效的架构。
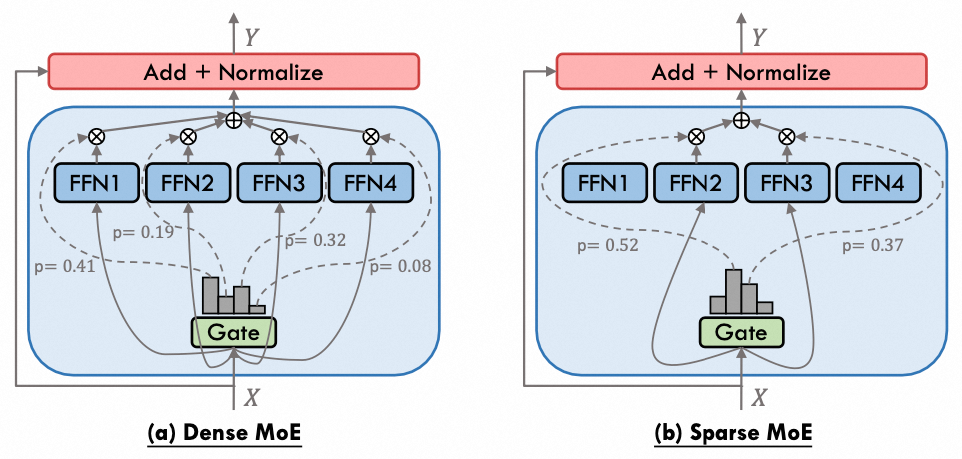
MOE可以分为Dense MoE和Sparse MoE两种类型。Dense MoE的特征在于所有专家都会被激活,只是每个专家承担的权重不同,可以理解为一种加权投票机制,每个专家负责不同的能力。然而,这种架构并不能减少计算量。相较之下,Sparse MoE只选择性激活TopK个专家,从而显著降低计算量。因此,DeepSeek选择采用Sparse MoE架构。
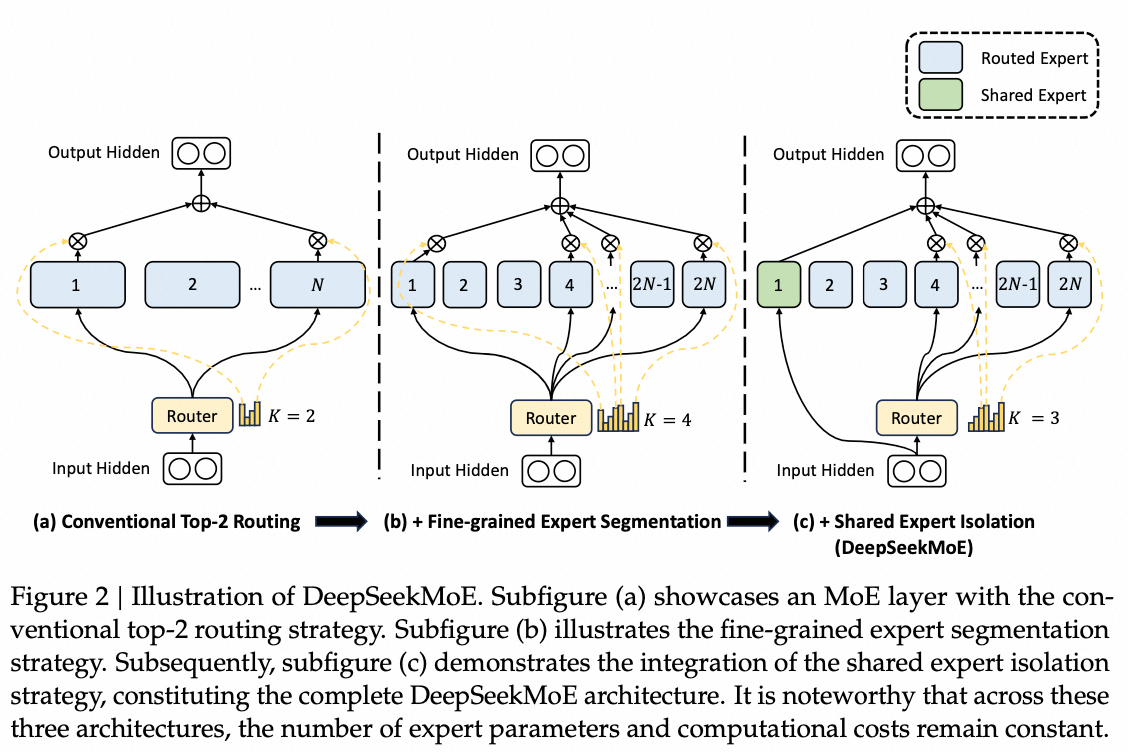
在DeepSeekMoE模型中,相较于传统的Naive Sparse MoE,有两项主要改进。首先,DeepSeekMoE将专家(Expert)的数量增加了一倍,这样每个专家可以学习到更加差异化的知识。其次,模型引入了共享专家(Shared Expert)。在传统的路由策略中,被分配给不同专家的token可能共享某些知识或信息。因此,不同专家可能在各自的参数中包含相同的知识,这导致参数的冗余。通过引入专门用于捕获和整合这些共同知识的共享专家,可以有效地缓解路由专家之间存在的参数冗余问题。
自动学习到的路由策略可能会遇到负载不均衡(load imbalance)的问题,这表现为两个显著的缺陷。首先,存在路由崩溃的风险,即模型总是只选择少数专家,导致其他专家无法得到充分的训练。其次,如果专家分布在多个设备上,负载不均衡会加剧计算瓶颈。
解决负载均衡常用的方法是Switch Transformer中提出的辅助Loss:

$f_i$即真实分配给expert $i$ 的概率,$P_i$ 为模型计算的分配给expert $i$ 的概率。文中认为loss会在 $f$ 和 $P$ 都是均匀分布时最小,此时每个专家被分配的概率都是相等的。例如有两个专家,那么loss的值为[0.5,0.5] * [0.5,0.5] = 0.5。但是这个结论是错误的:
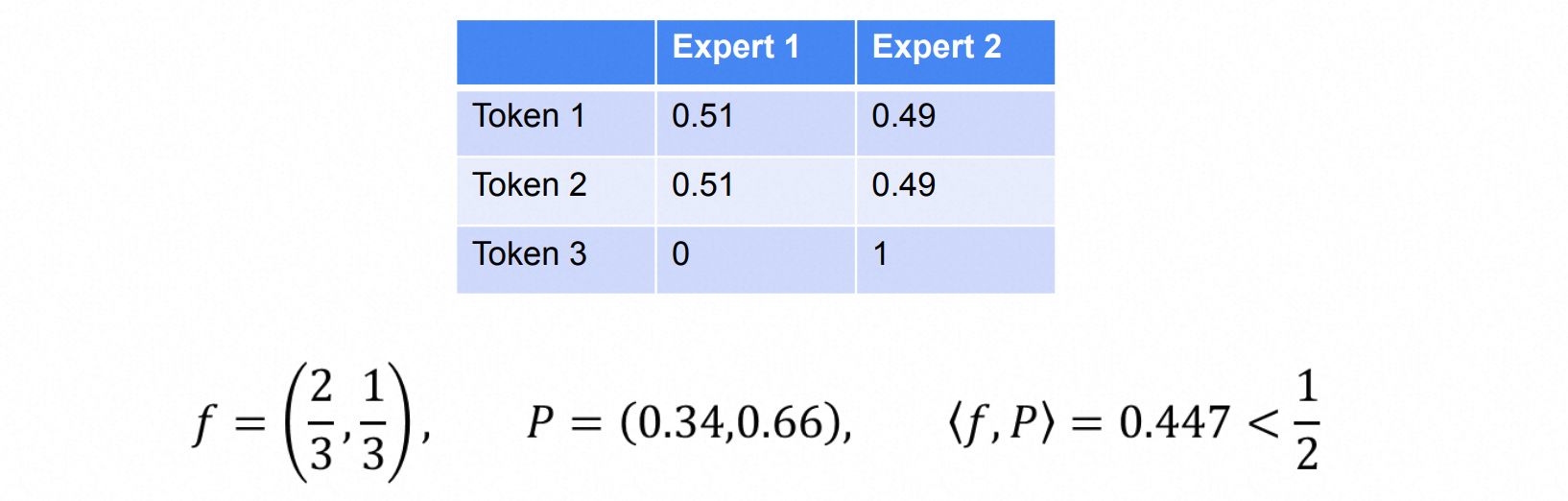
另外从直觉上,最小化这个loss意味着最小化 $\langle f, P \rangle$,而内积代表了相关性,这也并不合理。除此之外,这个辅助Loss只是想在expert之间做负载均衡,loss过大也会影响模型效果。
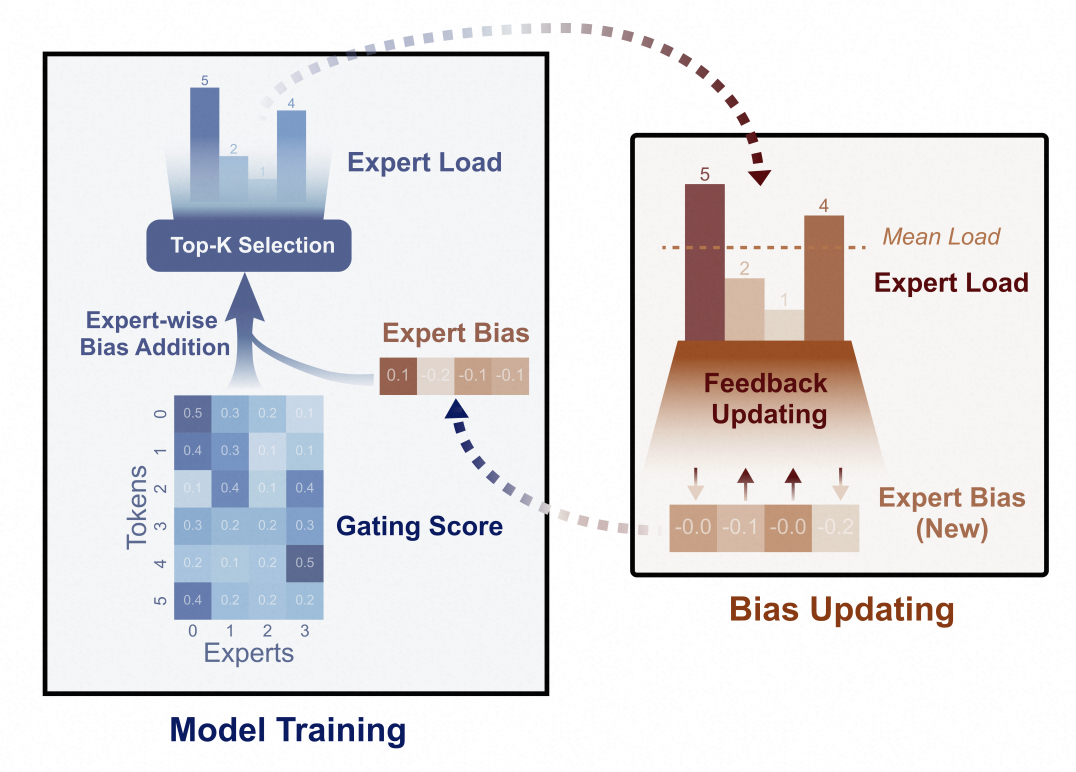
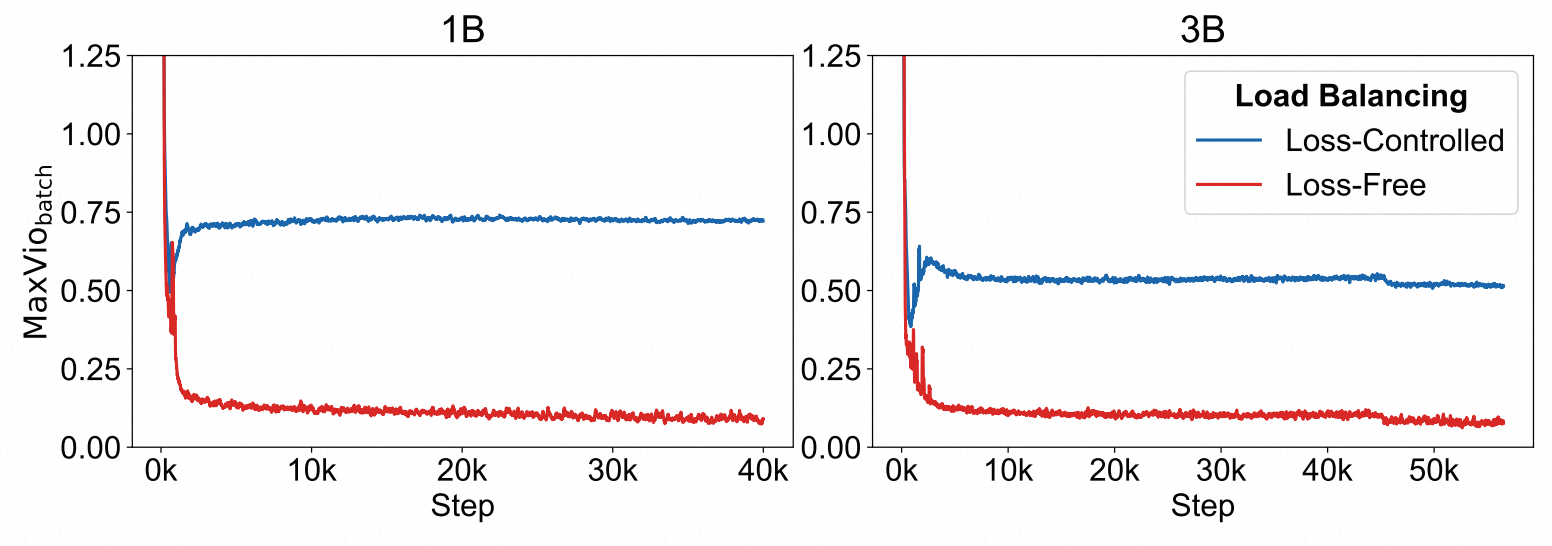
DeepSeek提出Loss Free的方法来解决负载不均衡的问题。在计算gate softmax时考虑此时每个expert的分配情况,从而进行动态调整权重。
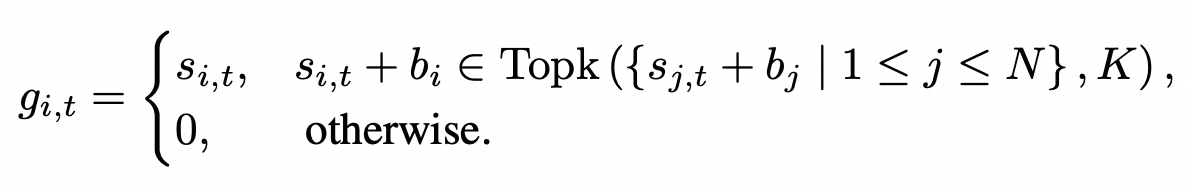
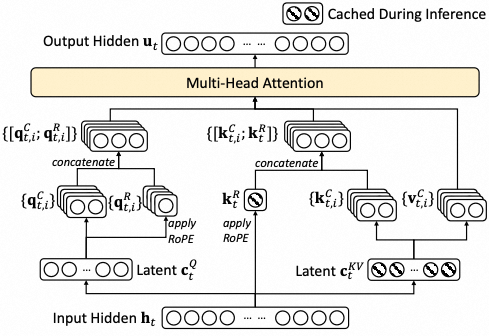
3.2. MLA
MLA(Multi-head Latent Attention)的核心思想是通过压缩KV,降低KV Cache存储压力,这是DeepSeek降本的核心设计之一。
Self Attention的核心思想是每个token的表示都是所有token的加权求和,权重即为token之间的correlation。每个Q、K、V都会被切成若干个head。
$$ \begin{aligned} \mathbf{q}_t &= W^Q \mathbf{h}_t = [\mathbf{q}_{t,1}; \mathbf{q}_{t,2}; \ldots; \mathbf{q}_{t,n_h}], \\ \mathbf{k}_t &= W^K \mathbf{h}_t = [\mathbf{k}_{t,1}; \mathbf{k}_{t,2}; \ldots; \mathbf{k}_{t,n_h}], \\ \mathbf{v}_t &= W^V \mathbf{h}_t = [\mathbf{v}_{t,1}; \mathbf{v}_{t,2}; \ldots; \mathbf{v}_{t,n_h}], \\ \mathbf{o}_{t,i} &= \sum_{j=1}^{t} \text{Softmax}_j \left( \frac{\mathbf{q}_{t,i}^T \mathbf{k}_{j,i}}{\sqrt{d_h}} \right) \mathbf{v}_{j,i}, \\ \mathbf{u}_t &= W^O [\mathbf{o}_{t,1}; \mathbf{o}_{t,2}; \ldots; \mathbf{o}_{t,n_h}], \end{aligned} $$主流的LLM均为Casual Decoder架构,每个token只能看到前序的token,不能看到后面的token。如果每个token生成时都重新计算前序所有token的KV会产生大量的冗余计算。因此可以把之前计算好的KV缓存下来,以空间换时间,这就是所谓的KV Cache。
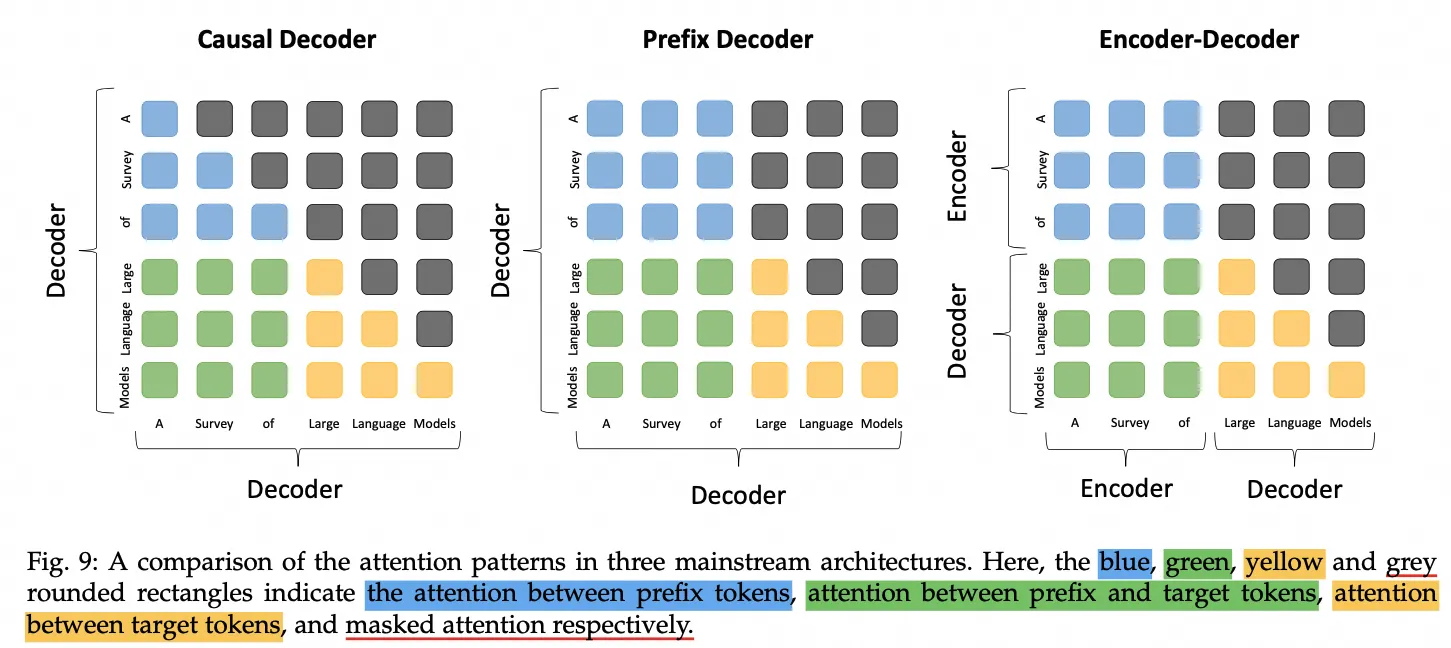
当token数较多时也会带来性能瓶颈,因此产生了GQA和MQA这种工作。
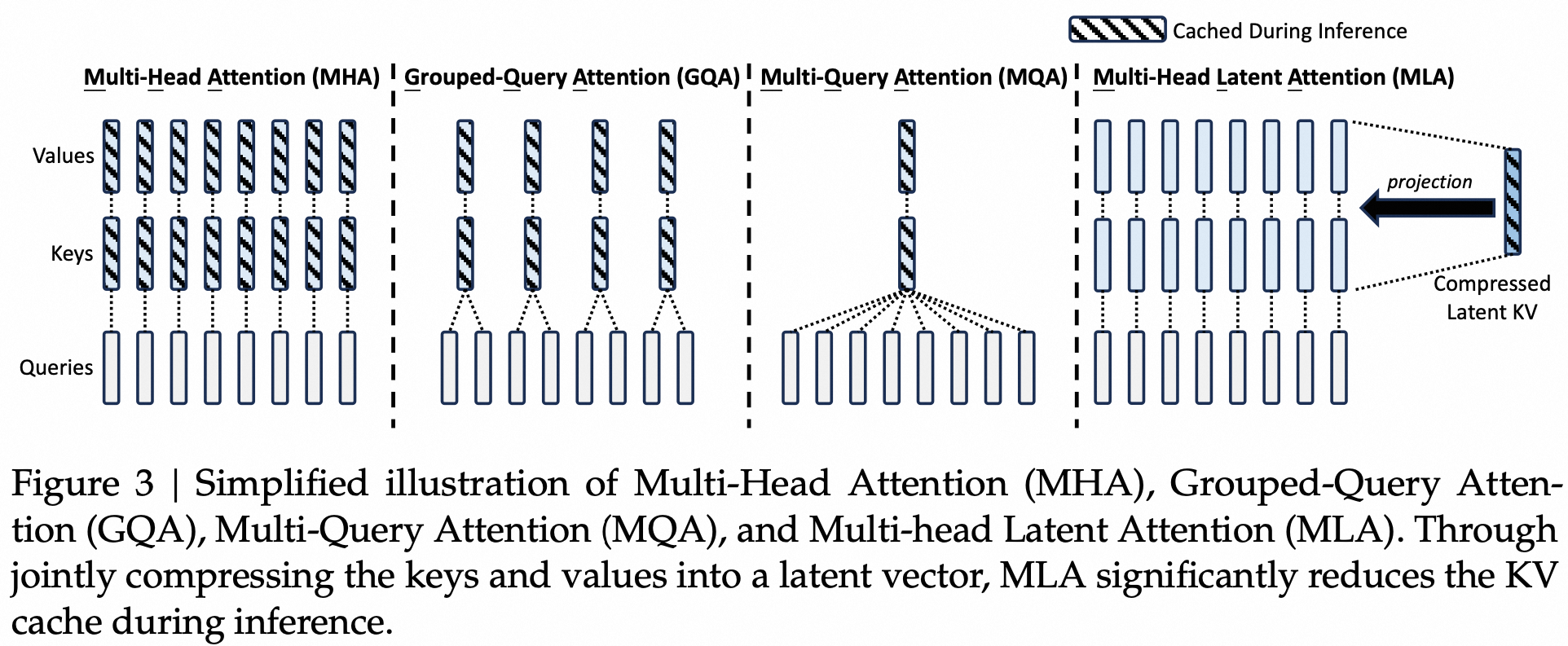
MLA核心思路是将KV映射到一个语义空间,需要的时候再进行还原,这样大大降低了Cache大小。
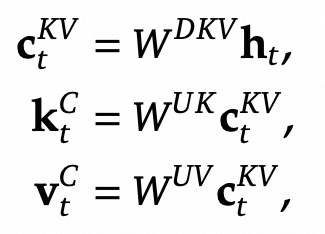
另外在推断的时候,$W^{UK}$ 能被吸收到 $W^Q$ 中,$W^{UV}$ 能被吸收到 $W^O$ 中,因此并不需要按公式还原出 $K$ 和 $V$,这也意味着计算也是在Latent Space的,和Stable Diffusion等工作的思路很相似。我们以 $W^{UK}$ 为例,计算分数时:
$$ q^T k = (W^Q h)^T (W^{UK} c^{KV}) = h^T [(W^Q)^T W^{UK}] c^{KV} = h^T W^Q_{new} c^{KV} $$在上述计算过程中,位置向量未被考虑。Transformer中的位置编码通常分为三类:1)绝对位置编码:为每个位置分配一个可训练或固定的位置向量,应用到token embedding上。其优点在于简单实现,但缺点在于扩展性差,并且不包含相对位置信息。例如,位置0和位置1之间的差异无法与位置1和位置200之间的差异呈现实际对比。2)相对位置编码:应用到查询(Q)和键(K)上,具有较好的扩展性。然而,计算开销较大,并且不适用于KV Cache架构。3)旋转位置编码(RoPE):结合了绝对和相对位置编码的优点。通过向量旋转的方式,旋转角度与绝对位置线性相关,同时在QK计算中能够体现相对位置信息。
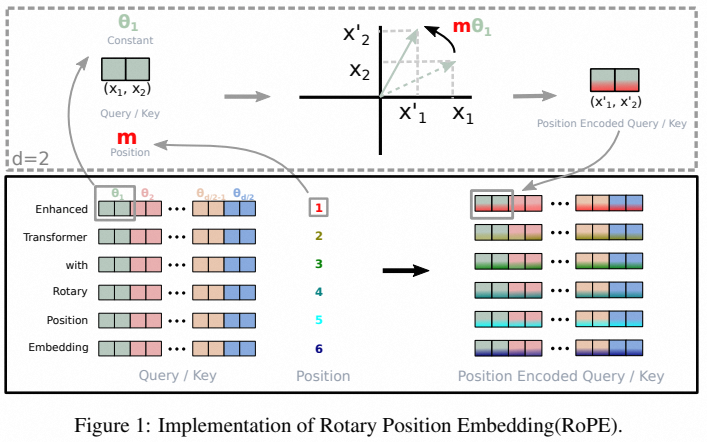
然而将RoPE直接应用到MLA中会导致 $W^{UK}$ 不能被吸收到 $W^Q$ 中,导致MLA的计算开销增大。具体来说:
$$ \begin{aligned} \text{RoPE}(q_t)^T \text{RoPE}(k_m) &= (R^q_t q_t)^T (R^k_m k_m) \\ &= q_t^T (R^q_t)^T R^k_m k_m \\ &= (W^Q h_t)^T (R^q_t)^T R^k_m (W^{UK} c^{KV}_m) \\ &= h_t^T (W^Q)^T \overline{(R^q_t)^T R^k_m} W^{UK} c^{KV}_m \end{aligned} $$中间的两个旋转矩阵是和位置相关的,因此 $W^{UK}$ 不能被吸收到 $W^Q$ 中,需要每次重新计算。论文提出使用额外的一些head计算位置向量,然后再拼到QK中。这意味着也要同时缓存 $k^R_t$。
3.3. MTP
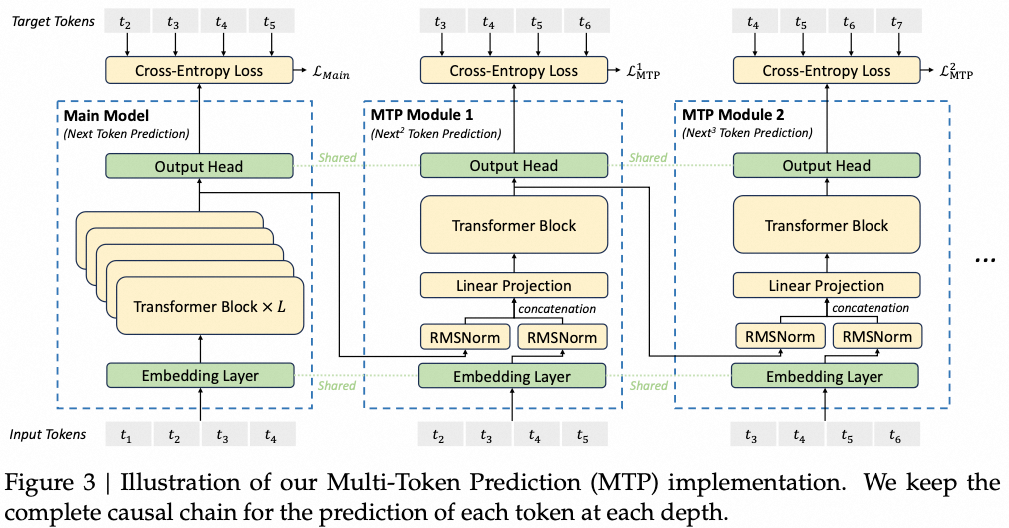
DeepSeek MTP(Multi-Token Prediction)能够提升数据利用效率,也提升了模型的规划能力。主要受两篇工作启发得到,一是提升训练效率的Google MTP,二是提升推理效率的EAGLE。
传统的语言模型(LLM)在训练时通常只关注于预测下一个可能的Token。这种方法存在两个明显的局限性。首先,由于训练的信号较弱,模型对那些在句子中起重要转折作用的词汇(Hard Transitions Token)往往关注不足。其次,这种逐词预测的方式缺乏全局的规划能力,而人类在组织语言时通常是以段落为单位进行构思,而不是逐词考虑。基于上述背景,Google提出MTP,把模型最后一层的Head进行分组,每一层分别预测不同位置的token。
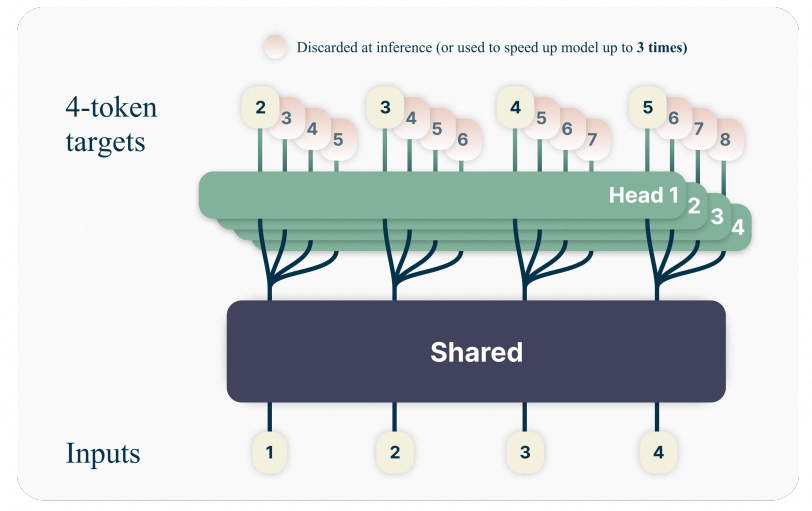
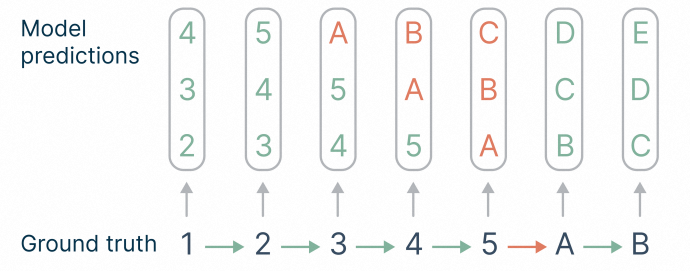
从结果上来看,引入MTP后模型效果得到明显提升。从分析上来看,模型增加了对hard transition token的训练信号。如下图所示,如果只预测next one,那么"5->A"的训练信号只有1/7=14%,而预测next three时,hard transition token占比为6/21=28%,可以看到训练信号大幅增加。但MTP训练时每个分组head都是独立的(parallel heads),这违背了自回归的设计原则。
另一篇借鉴的工作是大模型推理加速相关工作-Speculative Decoding.

EAGLE是Speculative Decoding一篇知名工作,文中验证了Causal Heads优于Parallel Heads。因此deepseek将MTP中的Parallel Heads改成Causal Heads.
4. 基础设施
4.1. 计算集群
DeepSeek-V3在配备有2048块NVIDIA H800 GPU的集群上进行训练。H800集群中的每个节点包含8块通过NVLink和NVSwitch连接的GPU。在不同节点之间,使用InfiniBand (IB)互连来实现通信。
4.2. DualPipe
流水线并行是一种提高计算效率的方法,通过将任务分解为多个阶段,并在不同计算单元之间传输数据,从而实现多个任务的重叠执行。具体来说,流水线并行像工厂流水线一样,将一项任务分成多个连续的步骤,每个步骤由不同的计算单元(例如处理器或加速器)负责。这种并行化可以显著减少模型训练或推理的时间。模型做一轮forward和backward的过程如下,我们会发现后面层需要等前面的计算完才能开始计算,会导致GPU在一段时间是闲置的。空白部分所表示的时间段里,总有GPU在空转。在Gpipe中,将阴影部分定义为bubble。
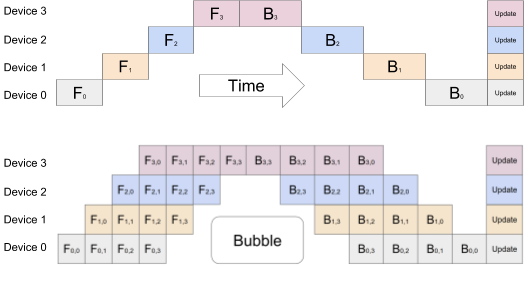
对于 DeepSeek-V3,由跨节点专家并行引入的通信开销导致计算与通信比率约为 1:1,这种情况效率较低。为了解决这一挑战,deepseek设计了一种创新的流水线并行算法,称为 DualPipe。该算法通过有效地重叠正向和反向的计算—通信阶段,加速了模型训练,并减少了流水线气泡。DualPipe 的核心理念是重叠单个正向和反向片段中的计算和通信。具体来说,我们将每个片段分为四个组成部分:注意力(attention)、全对全调度(all-to-all dispatch)、多层感知器(MLP)和全对全组合(all-to-all combine)。例如AB两个块,A块在前向计算时,B块做反向传播的通信,反之亦然。
“全对全”(“all-to-all”)通常用于描述一种网络通信模式,其中每个节点都需要与系统中的其他所有节点进行数据交换。这种通信模式常用于分布式计算和并行计算框架中,以便协调多个计算节点之间的数据共享和同步。

通过这种方式,大幅提高了GPU利用率:

4.3. FP8 Training
通常我们训练神经网络模型的时候默认使用的数据类型为FP32,而混合精度训练是指在训练的过程中,同时使用FP32和低精度(FP16、FP8),从而在尽量保持模型精度持平的条件下,加快训练时间、减少训练时内存占用。Deepseek提出了一种用于FP8训练的混合精度框架。在这个框架中,大多数计算密集型操作在FP8中进行,而一些关键操作则战略性地保持其原始数据格式,以平衡训练效率和数值稳定性。模型效果损失能够稳定控制在**0.25%**以内。
为了提升模型效果设计了两种优化手段:
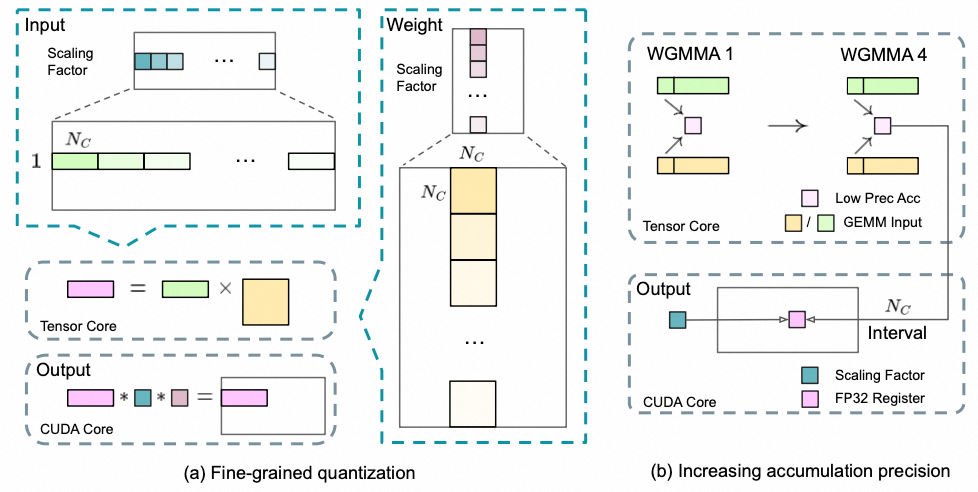
- 细粒度量化. 在低精度训练中,FP8格式因其有限的动态范围而面临溢出和下溢的问题。传统方法通过缩放输入张量来缓解,但对异常值敏感。为解决此问题,deepseek提出更细致的量化方法:对激活值以1x128的块缩放,对权重以128x128的块缩放。这种方法提高了量化过程对异常值的适应性。
- 提高累积精度. 低精度GEMM(广义矩阵乘法)操作常面临下溢问题,累加精度依赖高精度处理,通常是FP32。然而,在NVIDIA H800 GPU上的FP8 GEMM累加精度仅约14位,低于FP32。为解决此问题,我们建议将运算提升到CUDA核心,以实现更高精度。具体过程在Tensor核心上执行MMA时,使用有限位宽累加中间结果,达到𝑁𝐶间隔时,将部分结果复制到CUDA核心的FP32寄存器进行全精度FP32累加。
5. RL训练策略
预训练部分较为常规,我们重点关注R1涉及到的RL训练策略。
5.1. O1引发的推理研究热潮
gpt-o1的推出引发了推理研究的热潮,研究重点为构造COT推理数据。奖励设计可分为结果监督(ORM)和过程监督(PRM),另外也有研究基于搜索的方法,例如MCTS.
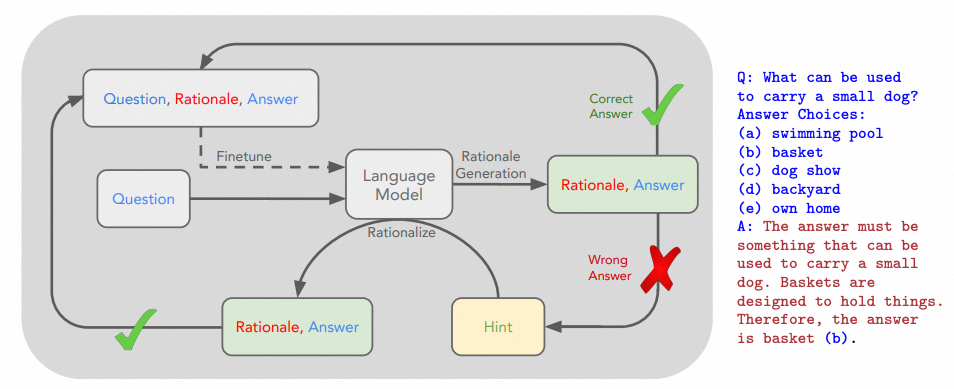
ORM的代表工作为StaR,提出自举式数据生成方案,大幅提升了模型推理能力。首先根据原始问题让大模型生成<答案,推理>对,对于答案生成正确的作为可用微调样本。对于错误答案的,根据答案提示让模型有更大概率生成更好的解释,然后用于训练中间模型。最终训练模型时,只利用能推理出正确答案的样本,对于不能生成正确答案的直接丢弃。方法有个明显缺陷是对于推理过程没有校验,即使答案正确推理也有可能是错误的,尤其是对于二元判别,生成数据噪声比较大。
OpenAI在2023年的研究成果显示,通过过程监督训练出的奖励模型比结果监督更可靠。他们利用先进的过程监督方法解决了78.2%的MATH测试集问题,并证明大型奖励模型可以有效地指导小型奖励模型进行类似人类的监督,可用于高效的大规模数据收集。

5.2. 从PPO到GRPO
强化学习是一种通过试错和从环境反馈中学习以优化序列决策问题的机器学习方法。游戏是一个典型的序列决策问题,玩家需要根据当前状态(State)做出决策(Action),目标是获得游戏胜利(Reward)。强化学习的目标是最大化Expected Reward。
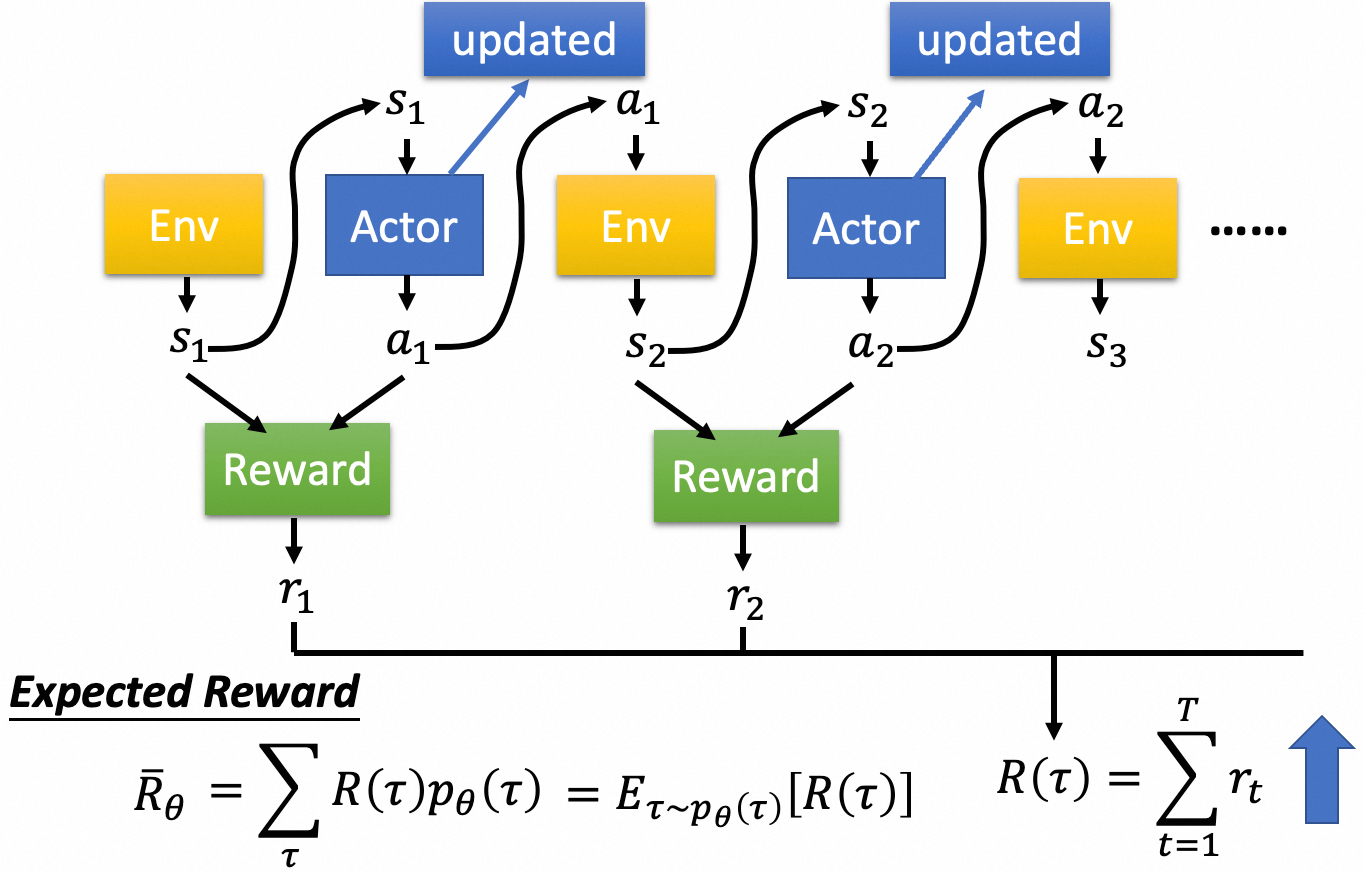
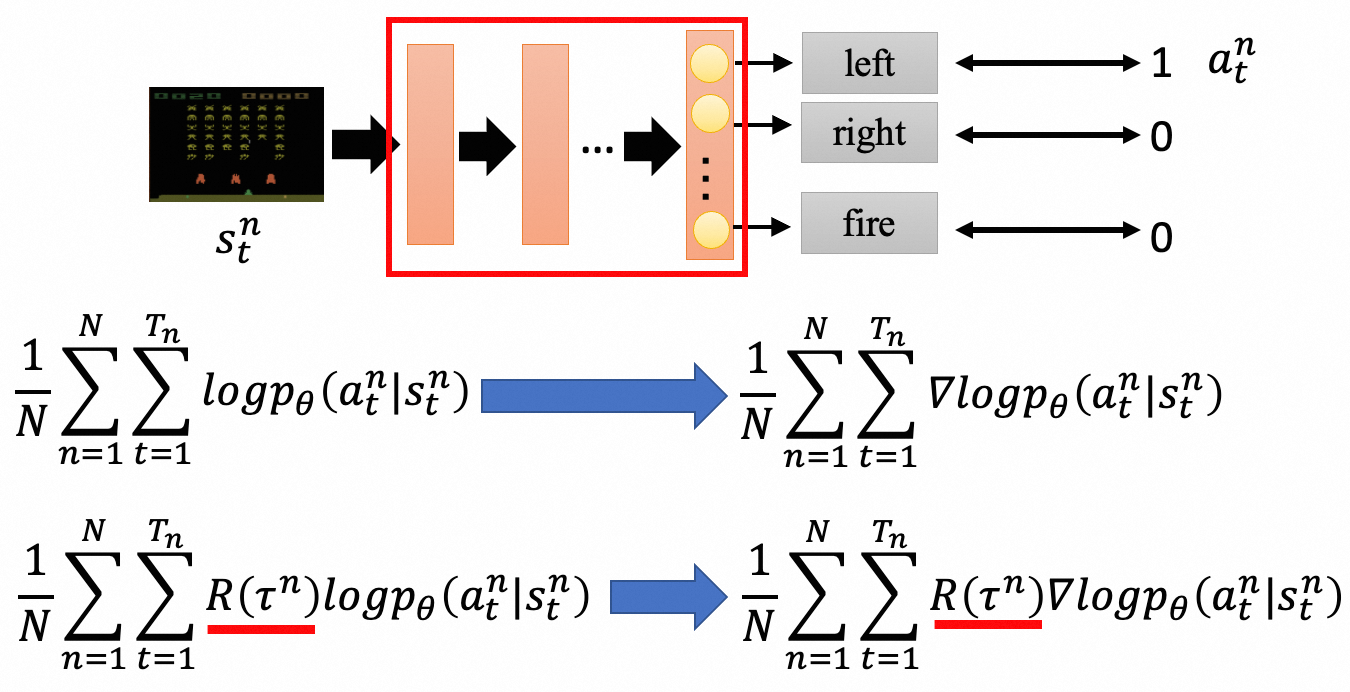
策略梯度(Policy Gradient)是一个比较直观的方法,直接利用梯度上升来最大化期望Reward. 下面是一个示例,输入是游戏的一帧画面 $s^n_t$,然后利用神经网络进行表征学习,最后输出Action $a^n_t$。如果不考虑Reward,其优化目标就是一个的典型的分类问题。
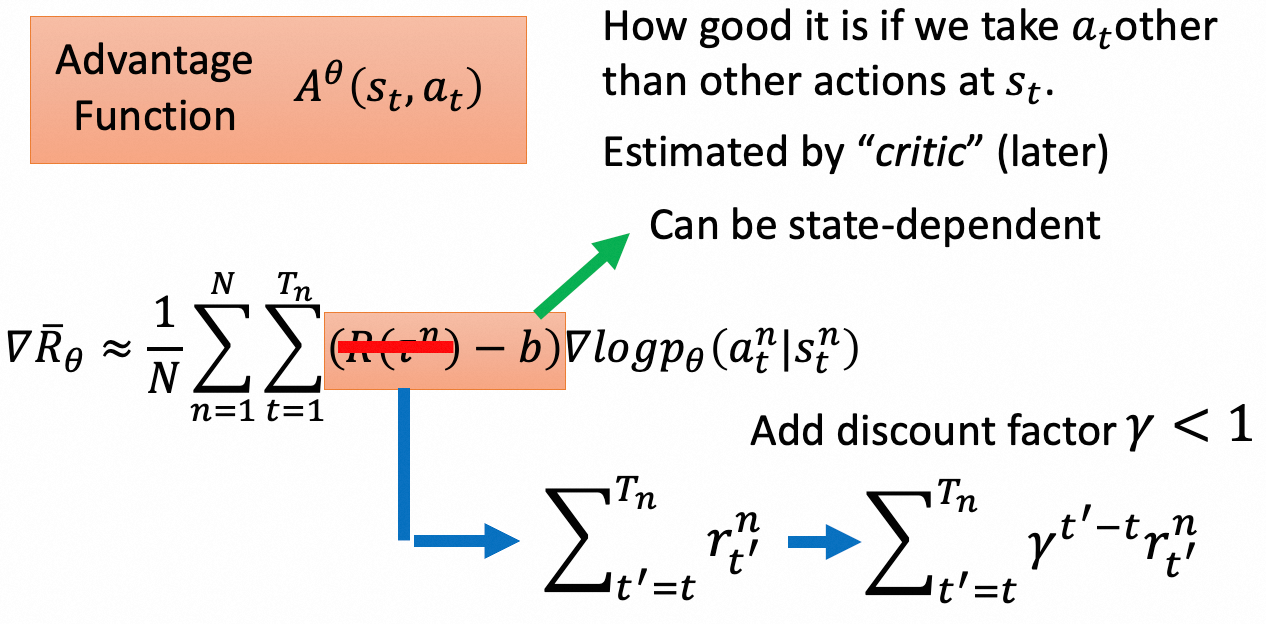
策略梯度有两个重要改进,一是考虑到有些场景reward都是正的,例如考试分数都会大于0,因此需要减去一个baseline让reward有正有负。二是对于一个采样而言,所有action都是利用相同的reward,即使最终游戏胜利,里面也会存在一些差的action,因此需要为每个action分配合理的reward,即在状态 $s$ 下采取 $a$ 的未来期望收益。改进后的这一项被称为优势函数 $A^\theta(s_t, a_t)$,用来衡量状态 $s$ 下采取 $a$ 的相对优势。优势函数可以用值函数计算:$A^\theta(s_t, a_t) = Q(s_t, a_t) - V^\pi(s^n_t) = r^n_t + \gamma V^\pi(s^n_{t+1}) - V^\pi(s^n_t)$。$r^n_t$ 指状态 $s_t$ 采取 $a_t$ 所获得的即时收益,$V^\pi(s^n_t)$ 指在策略 $\pi$ 下状态 $s_t$ 的未来期望收益。
计算优势函数有两种方法,一种是Monte-Carlo (MC),使用完整轨迹的奖励,缺点是方差很大,另一种是Temporal difference (TD),即采用一步轨迹的奖励,缺点是偏差太大。为了综合上述两种方法,常采用General Advantage Estimation (GAE),即多步TD加权求和:
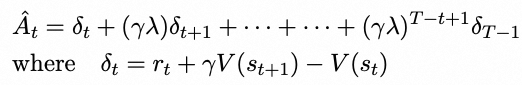
另一个要解决的问题是采样问题,回顾下PG目标 $\nabla \bar{R}_\theta = E_{\tau \sim p_\theta(\tau)}[R(\tau) \nabla \log p_\theta(\tau)]$,这里的采样 $\tau$ 依赖要训练的策略网络 $\pi_\theta$。当 $\theta$ 更新时,我们必须重新采样训练样本,这显然非常费时。因此我们想利用另一个策略 $\pi'_\theta$ 去采样多条数据,这样 $\pi_\theta$ 可以重复利用数据。这里利用了重要性采样公式:
$$ E_{x \sim p}[f(x)] = E_{x \sim q}\left[f(x) \frac{p(x)}{q(x)}\right] $$那么PG目标就变成:$\nabla \bar{R}_\theta = E_{\tau \sim p_{\theta'}(\tau)}\left[\frac{p_\theta(\tau)}{p_{\theta'}(\tau)} R(\tau) \nabla \log p_\theta(\tau)\right]$。当采样网络 $\pi'_\theta$ 和策略网络 $\pi_\theta$ 分布差异太大会导致效果不好,而PPO提出将两个分布的差异建模到Loss中,$J^{\theta^k}_{PPO}(\theta) = J^{\theta^k}(\theta) - \beta KL(\theta, \theta^k)$。PPO2更为简化:
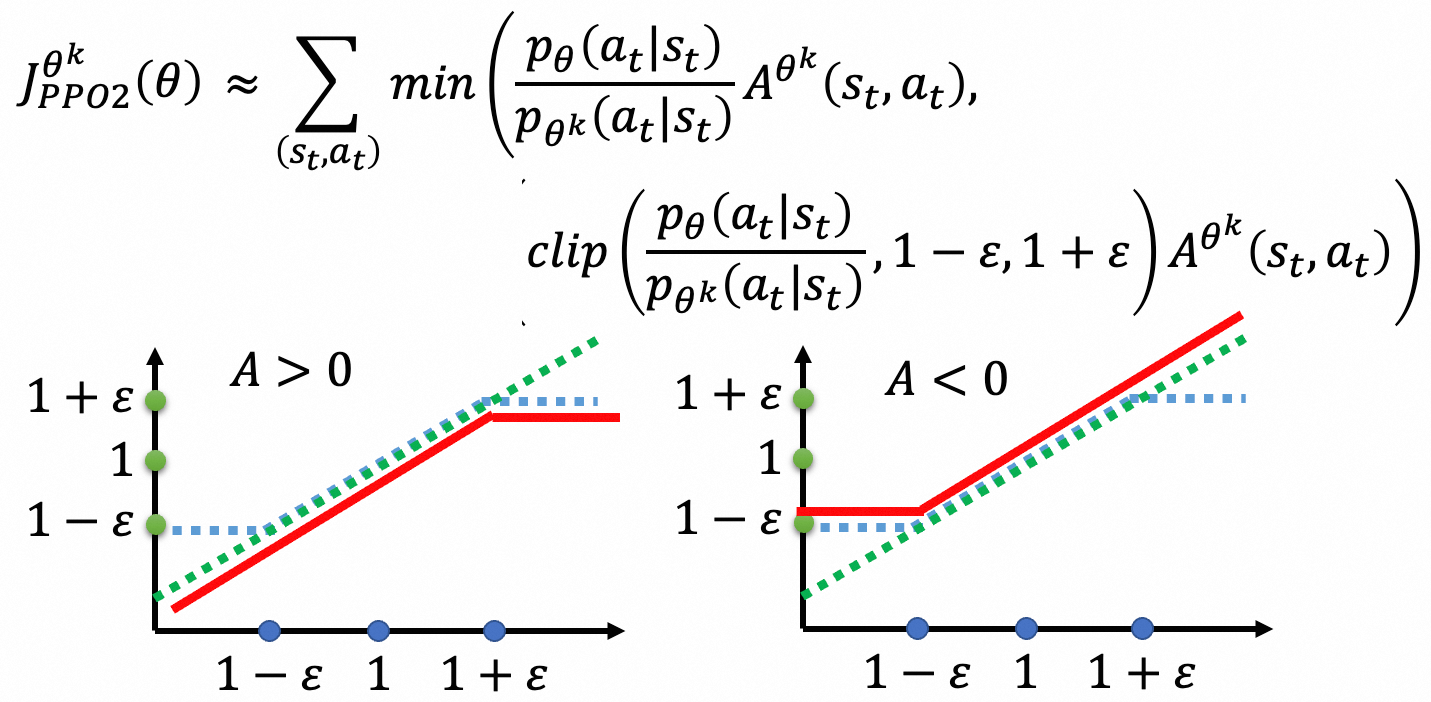
应用到LLM训练中,PPO的优化目标为:
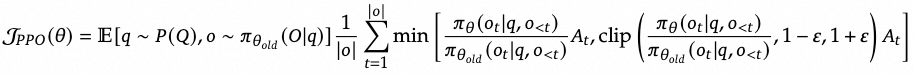
同时为了避免RL过度优化,导致模型通用能力退化,标准RLHF为每个token的reward增加了惩罚项,避免过度偏离参考模型:
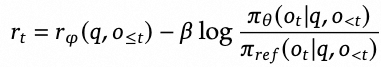
由于PPO中使用的价值函数通常是与策略模型规模相当的另一个模型,它带来了大量的内存和计算负担。此外,在强化学习训练中,价值函数被用作方差减少的基线。然而,在LLM的背景下,通常只有最后一个标记会被奖励模型赋予奖励分数,这可能使得训练一个在每个标记上都准确的价值函数变得复杂。为了解决这个问题,deepseek提出了GRPO(Group Relative Policy Optimization),它避免了像PPO那样需要额外的价值函数近似,而是使用响应同一问题生成的多个采样输出的平均奖励作为基线。
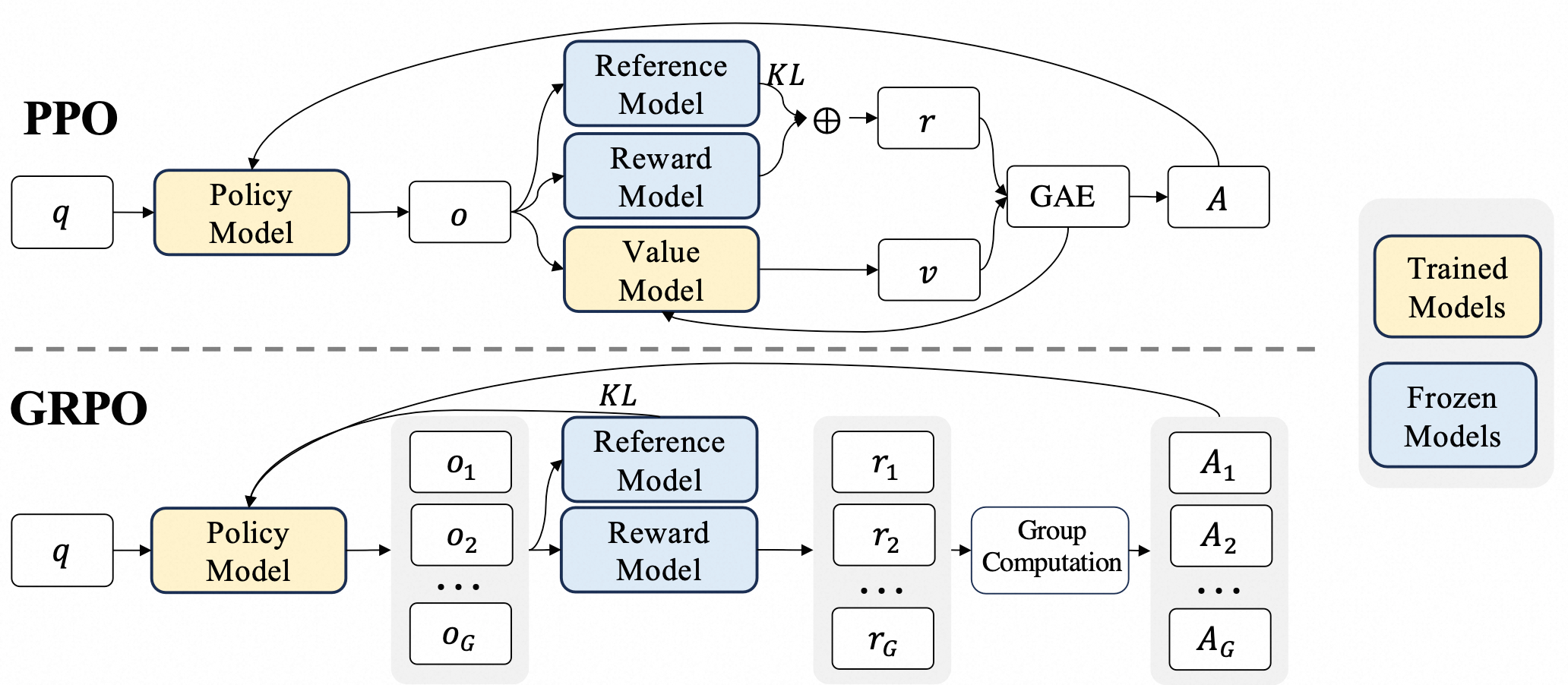
GRPO的优化目标如下:
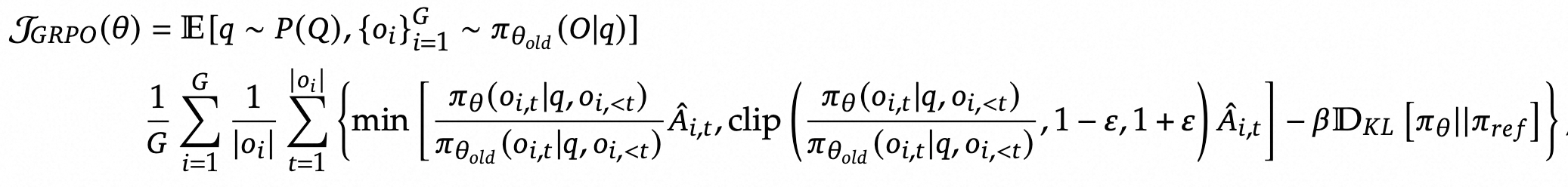
GRPO并没有在奖励中添加KL惩罚,而是通过将训练策略与参考策略之间的KL散度直接添加到损失中进行正则化,从而避免了复杂的 $\hat{A}_{i,t}$ 的计算。
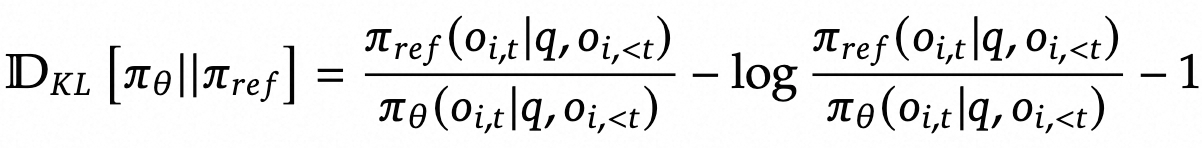
对于结果监督的RL(REINFORCE),优势函数计算如下:
$$ \hat{A}_{i,t} = \tilde{r}_i = \frac{r_i - \text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})} $$对于过程监督的RL(Actor-Critic),优势函数计算如下:
$$ \hat{A}_{i,t} = \sum_{\text{index}(j) \geq t} \tilde{r}^{\text{index}(j)}_i, \quad \tilde{r}^{\text{index}(j)}_i = \frac{r^{\text{index}(j)}_i - \text{mean}(\mathbf{R})}{\text{std}(\mathbf{R})} $$$$ \mathbf{R} = \{\{r^{\text{index}(1)}_1, \ldots, r^{\text{index}(K_1)}_1\}, \ldots, \{r^{\text{index}(1)}_G, \ldots, r^{\text{index}(K_G)}_G\}\} $$论文还验证了一个被广泛流传但未经充分验证的观点:代码训练可以提高推理能力。
作者将SFT, RFT, DPO, PPO, GRPO抽象为统一的范式:
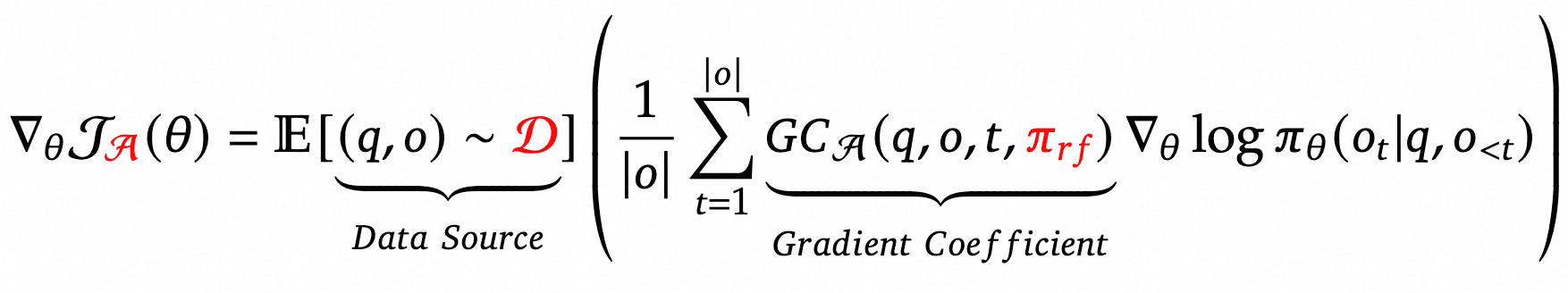
这里有三个关键组件:1)数据源 $\mathcal{D}$,决定训练数据;2)奖励函数 $\pi_{rf}$,训练奖励信号的来源;3)算法 $\mathcal{A}$:处理训练数据和奖励信号以获得梯度系数 $GC$,确定对数据进行惩罚或强化的幅度。

通过实验有两个观察:
- 数据源分为在线采样和离线采样,前者使用实时策略模型的采样结果,后者依赖初始SFT模型。观察表明,Online RFT在基准测试中明显优于RFT,特别是在训练后期,因为来自actor的采样数据表现出更显著的差异,实时数据采样带来了明显优势。
- 奖励函数被分为"规则"和"模型"两部分,其中"规则"评估答案正确性,而"模型"使用奖励模型对响应评分。GRPO和Online RFT的主要区别在于:GRPO根据奖励模型的奖励值调整梯度系数,能够区分强化和惩罚不同程度的响应,而Online RFT缺少这一特征,对所有正确的响应以相同强度进行强化。
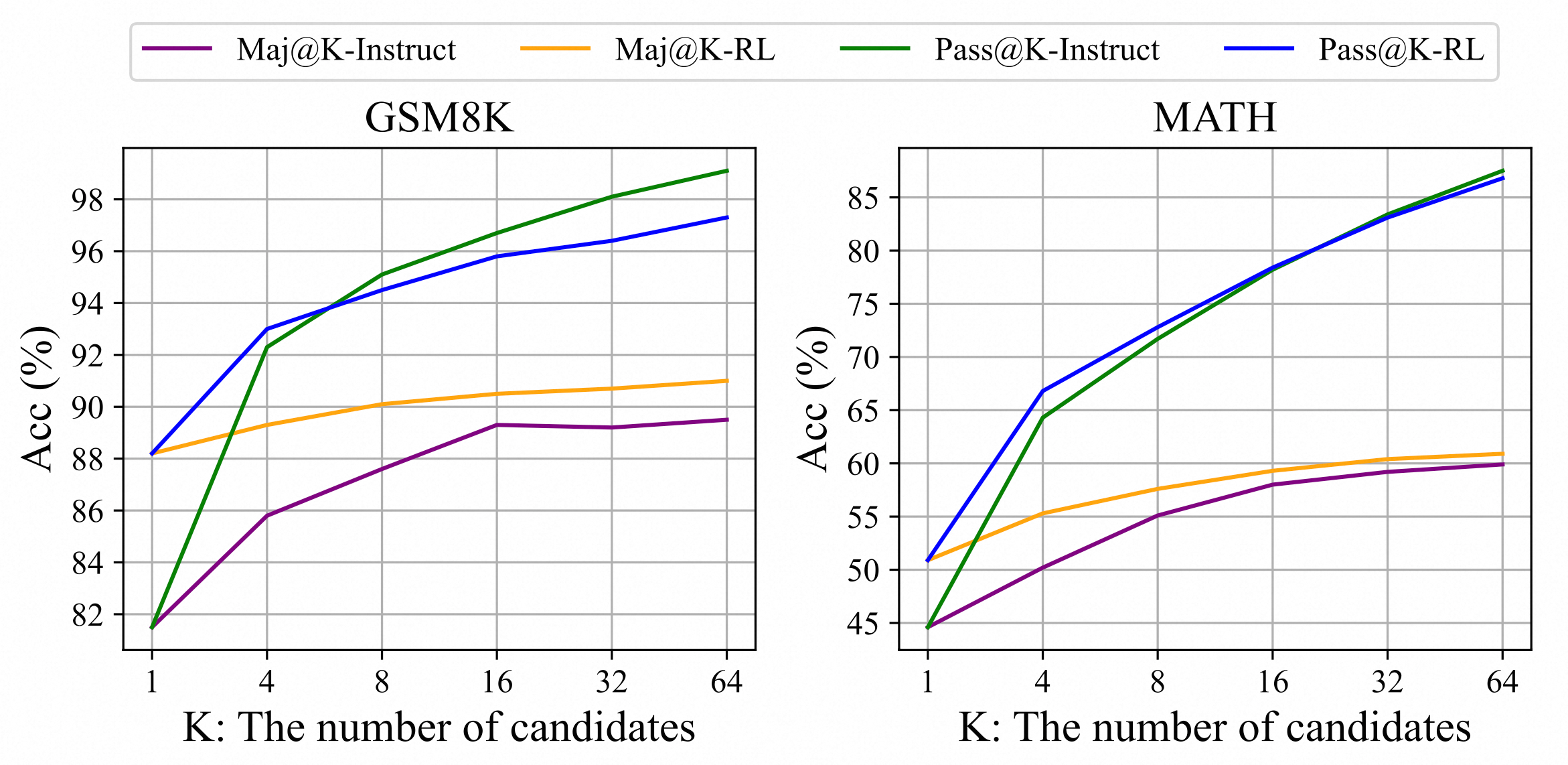
关于RL为什么有效,文章给出一个较为有趣的观察。通过评估Instruct和RL模型,发现RL提升了Maj@K的表现,但没有提升Pass@K。这些发现表明,RL通过使输出分布更加稳健来增强模型的整体性能,换句话说,这种改进似乎是由于提升了TopK中的正确响应,而不是增强了基本能力。
5.3. R1-Zero训练策略
R1-Zero不依赖监督数据,仅靠RL自驱学习就能达到很好的推理性能。R1-Zero用的强化学习算法就是上节的GRPO。设计了两个规则式Reward:
- 准确性奖励:准确性奖励模型评估响应是否正确。例如,对于具有确定性结果的数学问题,模型需要以指定格式(例如,在框内)提供最终答案,从而实现可靠的基于规则的正确性验证。同样,对于 LeetCode 问题,可以使用编译器根据预定义的测试用例生成反馈。
- 格式奖励:除了准确性奖励模型之外,我们还采用了一种格式奖励模型,要求模型将其思维过程置于 ‘
’ 和 ‘ ’ 标签之间。
用到的训练模板如下:

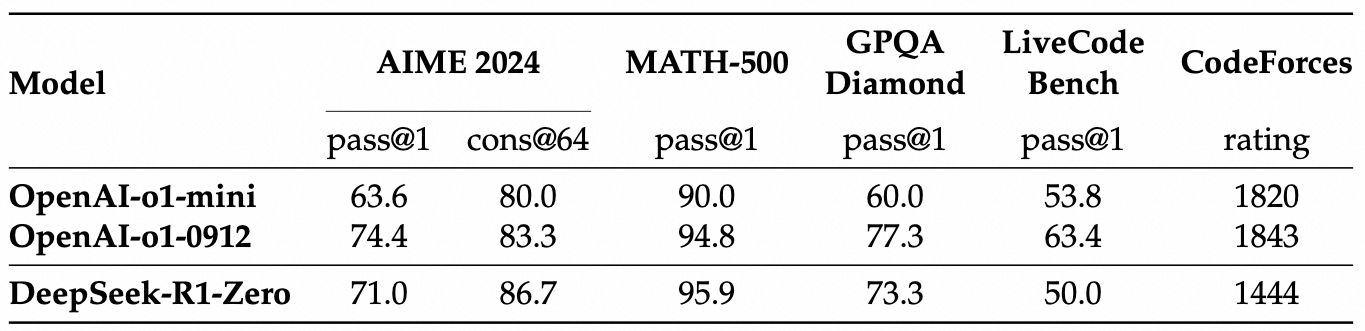
仅仅如此简洁的设计,在推理Benchmark上就达到了很高的水准:
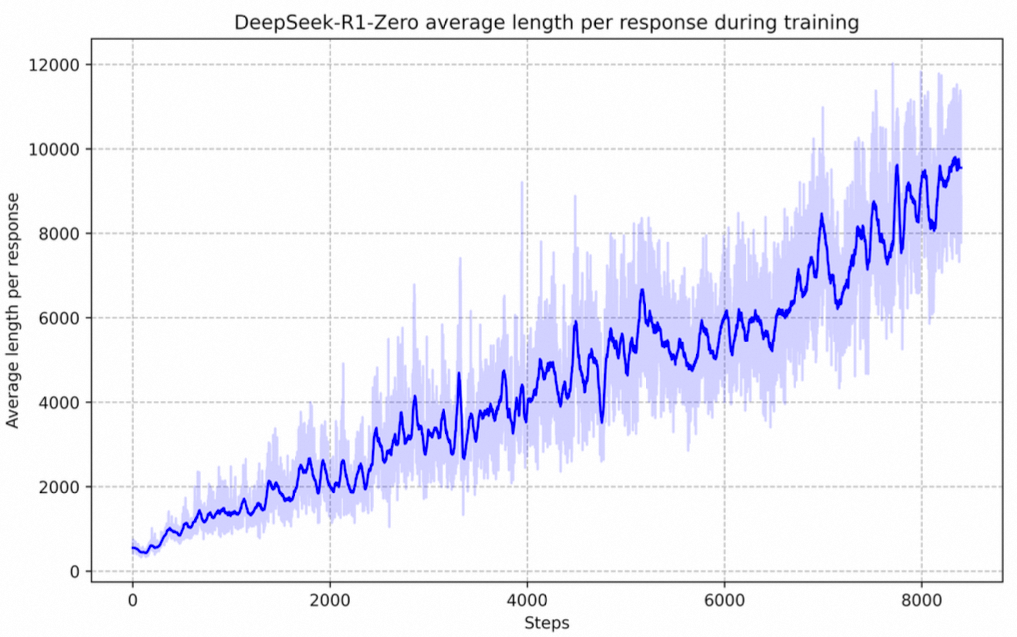
DeepSeek-R1-Zero在整个训练过程中,其思考时间呈现出持续的改进。这一进步并不是外部调整的结果,而是模型内部本质上的发展。DeepSeek-R1-Zero通过利用延长的测试时间计算,自然获得了解决越来越复杂推理任务的能力。这种计算涉及生成数百到数千个推理标记,使得模型能够以更深入的方式探索和完善其思维过程。
在DeepSeek-R1-Zero的训练过程中,观察到一个特别有趣的现象,即出现了**“顿悟时刻”(aha moment)**。这一时刻发生在模型的中间版本。在这个阶段,DeepSeek-R1-Zero通过重新评估其初始方法,学会将更多的思考时间分配给一个问题。此行为不仅证明了模型日益增强的推理能力,也是强化学习如何引导出意外且复杂结果的一个引人入胜的例子。已经有多个工作能够复现"aha moment"。

5.4. R1训练策略
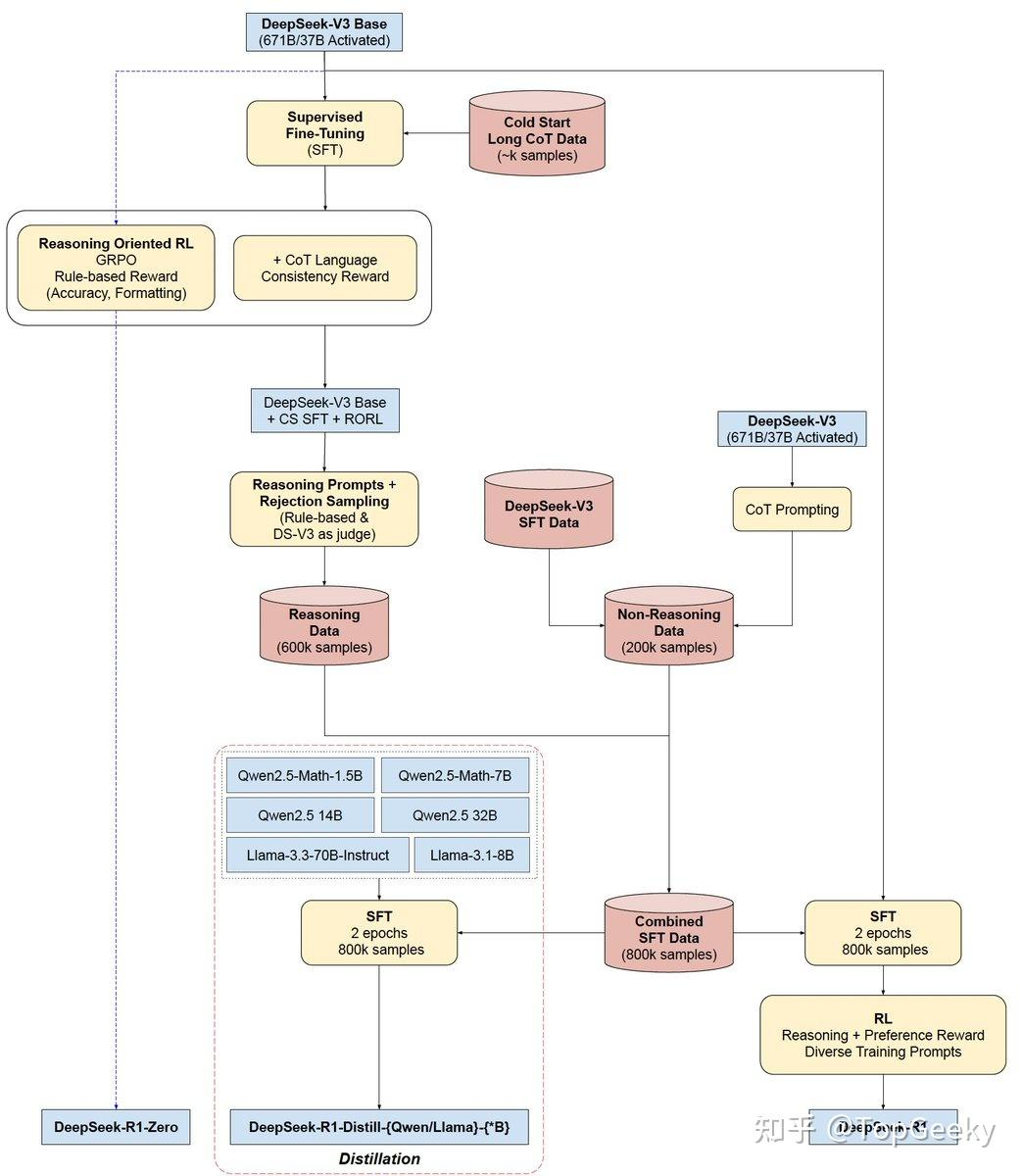
尽管DeepSeek-R1-Zero表现出强大的推理能力,并能自主发展出意想不到的强大推理行为,但它仍面临一些问题。例如,DeepSeek-R1-Zero在可读性较差和语言混合等方面遇到挑战。为了使推理过程更加可读,R1训练结合了少量冷启动数据。该流程分为四个阶段:
冷启动. 一开始要收集少量的Long-CoT数据来微调模型,目的是防止早期训练不稳定和可读性差问题。
推理导向的RL. 在对DeepSeek-V3-Base进行冷启动数据的微调后,采用与DeepSeek-R1-Zero相同的大规模强化学习训练过程。这一阶段的重点是提高模型的推理能力,尤其是在编码、数学、科学和逻辑推理等。为了缓解语言混合的问题,在RL训练中引入了语言一致性奖励,该奖励是根据CoT中目标语言单词的比例来计算的。虽然消融实验表明这种对齐会导致模型性能略有下降,但这一奖励符合人类偏好,使其更加易读。最后,通过直接相加推理任务的准确性和语言一致性奖励来形成最终奖励。然后对微调后的模型进行RL训练,直到在推理任务上达到收敛。
拒绝采样和SFT. 当面向推理的强化学习(RL)收敛之后,我们利用得到的检查点来收集用于下一轮的有监督微调(SFT)数据。与最初的冷启动数据主要关注推理不同,此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。具体来说,按照以下步骤生成800K训练数据,并对DeepSeek-V3-Base进行了两轮的微调。
推理数据. 编写了推理提示,通过拒绝采样从RL训练的检查点中生成推理轨迹。在前一个阶段,数据集中仅包含可以通过基于规则的奖励进行评估的数据。而在这一阶段,数据集得到了扩展,包含了一些使用生成式奖励模型产生的数据。此外,由于模型输出有时可能会显得冗长或难以理解,特意去除掉了混合语言、长段落及代码块中的链式思维。对于每个提示,生成了多个响应,但只保留了那些正确的版本。在整个过程中,收集了约60万条与推理相关的训练样本。
非推理数据. 对于不涉及推理的数据类型,包括写作、事实问答、自我认知和翻译,采用了DeepSeek-V3流程,同时重用了部分DeepSeek-V3的SFT数据集。在某些非推理任务中,通过提示在回答问题前调用DeepSeek-V3生成潜在的链式思维。但对于诸如"hello"这类简单的查询,则不提供链式思维作为回应。最终,收集了大约20万条与推理无关的训练样本。
面向所有领域的RL. 在第3阶段微调模型的基础上,进一步提升模型的有用性和无害性,同时改进其推理能力。对于推理任务,采用规则的奖励来指导。对于一般任务,采用奖励模型来对齐人类偏好。
蒸馏实验有两个发现,一是通过大模型蒸馏能够大幅提升小模型能力;二是小模型直接RL训练的效果不如蒸馏效果,这也反映了训练更大模型的必要性。

文章最后也提到了尝试PRM和MCTS的失败经历,探讨了这两种方法的弊端。
6. 参考文献
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
- DeepSeek-V3 Technical Report
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- DeepSeek分析-Semianalysis
- A Survey on Mixture of Experts
- Switch Transformers
- Switch Transformers课程
- Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
- RoFormer: Enhanced Transformer with Rotary Position Embedding
- Understanding Rotary Positional Encoding
- Better & Faster Large Language Models via Multi-token Prediction
- Fast Inference from Transformers via Speculative Decoding
- KOALA: Enhancing Speculative Decoding for LLM via Multi-Layer Draft Heads with Adversarial Learning
- EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
- MEDUSA: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads
- Introducing GPipe
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- Proximal Policy Optimization Algorithms
- Deep Reinforcement Learning, 2018
- PPO原理与源码解读
- DeepSeek V3解读
- STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
- Let’s Verify Step by Step
- 如何评价deepseek-R1与deepseek-R1-Zero模型?
- Evaluating Security Risk in DeepSeek
- How Far Are We From AGI: Are LLMs All We Need?