本文分享我们在电商领域智能体(Agent)方向所提出的综合性评估与训练框架。该框架通过构建电商虚拟环境、可扩展数据合成以及工具调用轨迹的蒸馏和强化学习等,赋予了Agent模拟真实用户的能力,擅长自动化地完成用券凑单、预算管理、特定卖家搜索等核心电商交互任务。根据该项工作总结的论文已被AAAI'26 录用为Oral,并应用于电商线上对话导购助手。
论文:ShoppingBench: A Real-World Intent-Grounded Shopping Benchmark for LLM-based Agents
1. 背景
现有电商领域的Agent相关工作(例如 WebShop)主要聚焦于简单的用户意图,如查找和购买商品。然而,现实世界中的用户往往追求更复杂的目标,例如使用优惠券、管理预算,以及寻找能同时销售多种商品的卖家。为弥合这一差距,我们提出了 ShoppingBench —— 一种新颖的端到端购物基准,旨在覆盖日益复杂的、具有实际场景依据的用户意图。
具体而言,我们设计了一个可扩展的框架,基于从真实商品样本中合成的多样化意图来模拟用户指令。为实现一致且可靠的评估,我们构建了一个大规模购物沙盒环境,包含超过 250 万件真实商品。在该环境下,我们评估了 17 个LLMs,结果显示,即便是表现最佳的 GPT-4.1 模型,成功率也低于 50%,充分体现了本基准的挑战性。
此外,我们提出了一种轨迹蒸馏策略,结合监督微调(SFT)与基于合成轨迹的强化学习(RL),将大型语言Agent的能力蒸馏到一个更小的模型中。最终,我们训练出的Agent在性能上可与 GPT-4.1 相媲美。
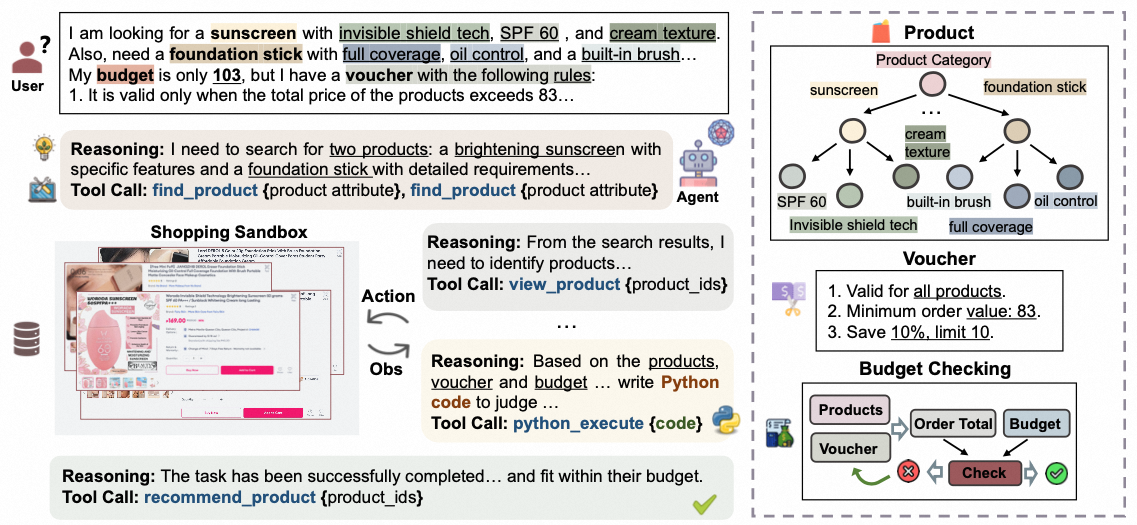
2. 数据集构建
2.1. 构建虚拟环境
当前,基于大语言模型(LLM)的Agent优化主要分为两类范式:Parameter-Driven 与 Parameter-Free。
- Parameter-Driven 范式依赖模型参数更新,包括基于监督微调(SFT)的方法(利用合成轨迹数据进行微调)和基于强化学习(RL)的方法(通过设计奖励函数实现偏好对齐);
- Parameter-Free 范式则无需修改模型参数,涵盖基于专家经验的 Prompt 优化、基于反馈机制的策略(如 ReAct、meta-prompt)、工具集增强、检索增强生成(RAG)以及多Agent协作架构(如 Planner 或 Workforce 模式)。
无论采用何种优化路径,均需一个高质量的基准(Benchmark)以支持快速迭代。理想的 Benchmark 应具备三方面特性:覆盖用户多样意图(全面性)、贴近真实世界(真实性)、评估指标与业务目标高度相关(有效性)。
在综合评估现有方案后,我们选定 ORM-Virtual(虚拟环境下的观测式回报建模)范式构建电商虚拟环境。相较于 PRM(仅适用于 Parameter-Driven 范式)和 ORM-Realistic(依赖高成本人工标注且难以扩展),ORM-Virtual 在可控性和可扩展性上更具优势。

具体而言,我们从电商平台上随机采样了超过250万件商品构建本地虚拟电商环境,环境中包含:
- 结构化的商品信息,其中部分关键属性使用 Qwen2.5-VL-72B-Instruct 抽取得到;
- 基于Pyserini开发的商品搜索引擎;
- 一套标准化工具集,包括商品搜索、查看商品详情、联网搜索、Python执行器等;
- 采用ReAct范式的Agent框架,支持主流大模型(如 gpt-4.1、Claude-4-Sonnet)等接入。
2.2. 可扩展的数据合成
ShoppingBench 数据集涵盖四类真实用户购买意图,难度逐级递增:
- 单品查找(Products Finder):Agent 需根据用户对商品属性的描述定位具体商品;
- 知识导购(Knowledge):Agent 需理解问题中隐含的知识并将其关联至对应商品。为挖掘需依赖外部知识才能完成的购物决策问题,我们基于 SimpleQA 数据集构建知识导购样本。该数据集包含 4000+ 问答对,GPT-4o 在无联网条件下的准确率仅为 38.2%。我们利用商品搜索引擎检索与答案相关联的商品,并经人工筛选得到 310 个有效的问答-商品对;
- 多品同店(Multi-products Seller):Agent 需找出能同时提供用户所列全部商品的店铺;
- 用券凑单和预算管理(Coupon & Budget):Agent 需解析优惠券规则,并在预算约束下推荐最优商品组合。针对电商平台复杂的用券规则,我们设计了该意图专属的合成 Pipeline: a. 随机选择优惠券类型(平台券或店铺券); b. 根据券类型选取 1 至 n 件跨店或同店商品; c. 从商品中随机抽取核心属性; d. 生成定额或折扣券,并基于商品总价设定门槛、面额、折扣率及封顶值,同时生成用户预算约束; e. 结合商品核心属性与券信息,使用 GPT-4.1 合成用户指令。
上述用户指令(以及后续章节中的工具调用轨迹训练样本)都可以用规则快速验证,无需或仅需轻量级人工参与,因此能够低成本、可扩展的批量合成。
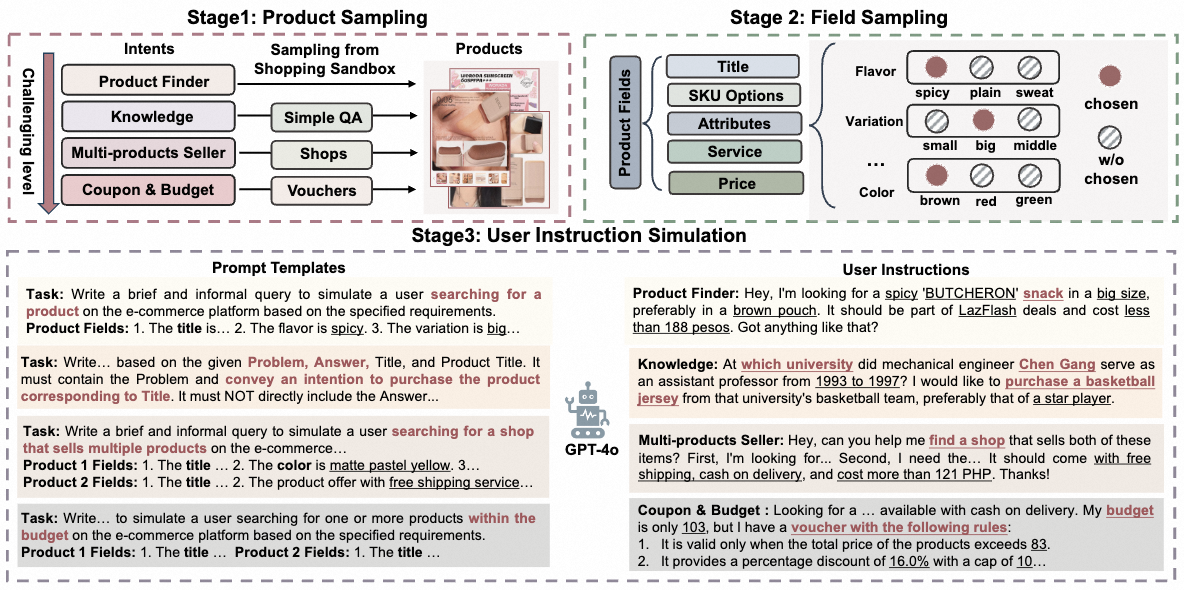
3. 方法
3.1. 合成工具调用轨迹
评估指标:我们针对各类用户意图定义了两项核心评估指标,即商品相关性的累积平均值(Cumulative Average of product Relevance, CAR)与绝对成功率(Absolute Success Rate, ASR):
- 商品相关性的累积平均值:衡量Agent推荐的商品属性和用户指令中要求的商品属性的匹配率。
- 绝对成功率:衡量所有的样本中,Agent推荐的商品的CAR和其他约束(例如,用券凑单意图要求商品的券后价低于用户预算)均完全满足用户要求的比例。
轨迹蒸馏:我们使用 GPT-4.1 从 2,410 条用户指令生成工具调用轨迹。我们采用拒绝采样策略,根据评估指标过滤低质量的轨迹,仅保留完全成功(ASR = 1)的样本。
3.2. 轨迹蒸馏和强化学习
轨迹蒸馏:我们从每条轨迹中采样多个步骤,最终构建包含 5,552 个步骤的训练数据集。模型输入包括用户指令及观测信息(例如检索到的商品列表),输出则由推理过程(reasoning trace)和下一步动作(即工具调用)组成。随后,我们在 Qwen3-4B 上执行 SFT,以提升模型理解复杂指令、处理多轮观测并准确预测动作的能力。
工具调用的强化学习:为进一步增强模型的工具调用能力,我们在 SFT 微调后的 Qwen3-4B 基础上,采用 GRPO 算法并结合工具奖励进行持续训练。奖励函数由格式奖励(format reward)和工具奖励(tool-calling reward)两部分构成,其中工具奖励根据Actor推理的工具与拒绝采样的“Ground-Truth”工具在名称、参数及参数值上的匹配度计算得出。
- Tool-calling reward:
$$R_{mat} = r_n + r_k + r_v \in [0, S_{max}]$$
- Tool name match rate $r_n$.
- Parameter names set match rate $r_k$.
- Parameter value match rate $r_v$.
where $S_{max}$ is max score of $R_{mat}$. Normalized as:
$$R_{tool} = 6 \cdot \frac{R_{mat}}{S_{max}} - 3 \in [-3, 3]$$- Format reward:
regex verifies the required JSON schema, correct $\to R_{format} = 1$, otherwise set 0.
- Final reward: $$R_{final} = R_{tool} + R_{format} \in [-3, 4]$$
3.3. 实验结果
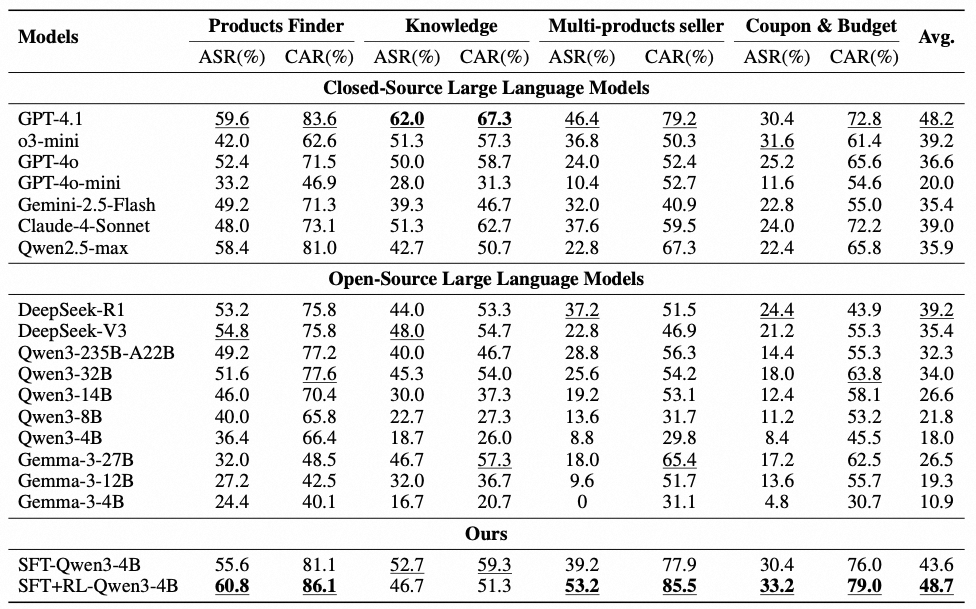
即使我们的样本都是使用GPT-4.1拒绝采样合成的,但经过SFT+GRPO训练后,除了依赖大量知识的“知识导购”意图,在“单品挑选”、“多品同店”和“用券凑单”意图上,我们的模型都超过了GPT-4.1:
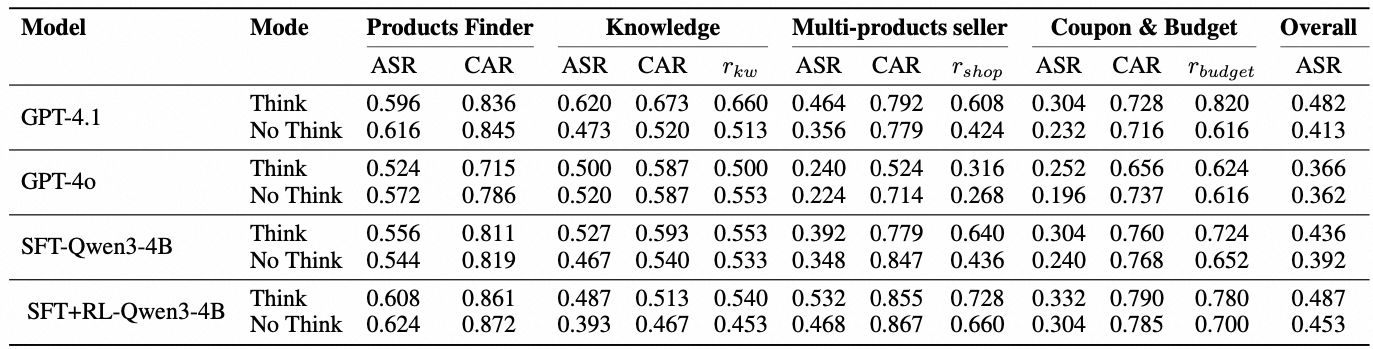
另外,我们对Think / No Think进行了消融实验,发现了当前业界流行的现象:
- Think并不一定适合所有的任务。去除think后,在相对简单的“单品挑选”上效果反而提升,而在“多品同店”、“用券凑单”意图上效果则显著下降。进一步分析发现,no think mode下,几乎所有意图的match score(商品属性匹配分)都有提升,但对于需要推理能力的shop score(所以商品都来自同一店铺)和需要逻辑和数学计算能力的budget score(商品的券后总价低于预算)会显著下降。
- 后续可以通过Post-Training训练模型根据任务特点在Think Mode和No Think Mode间自适应切换,避免在简单任务上产生效果损失。
4. 应用
我们基于ShoppingBench框架,以Qwen3-30B-A3B模型为基座训练和开发了Agentic模式的导购助手,它能根据用户Query自适应的进行决策和调用工具,在复杂意图下带来了明显的提升:
| 用户复杂Query | Workflow版 | Agentic版 |
|---|---|---|
| recommend 2025 nba champion jersey(推荐2025年nba的冠军球衣) | 找到了一些球衣,但不是2025冠军雷霆队的球衣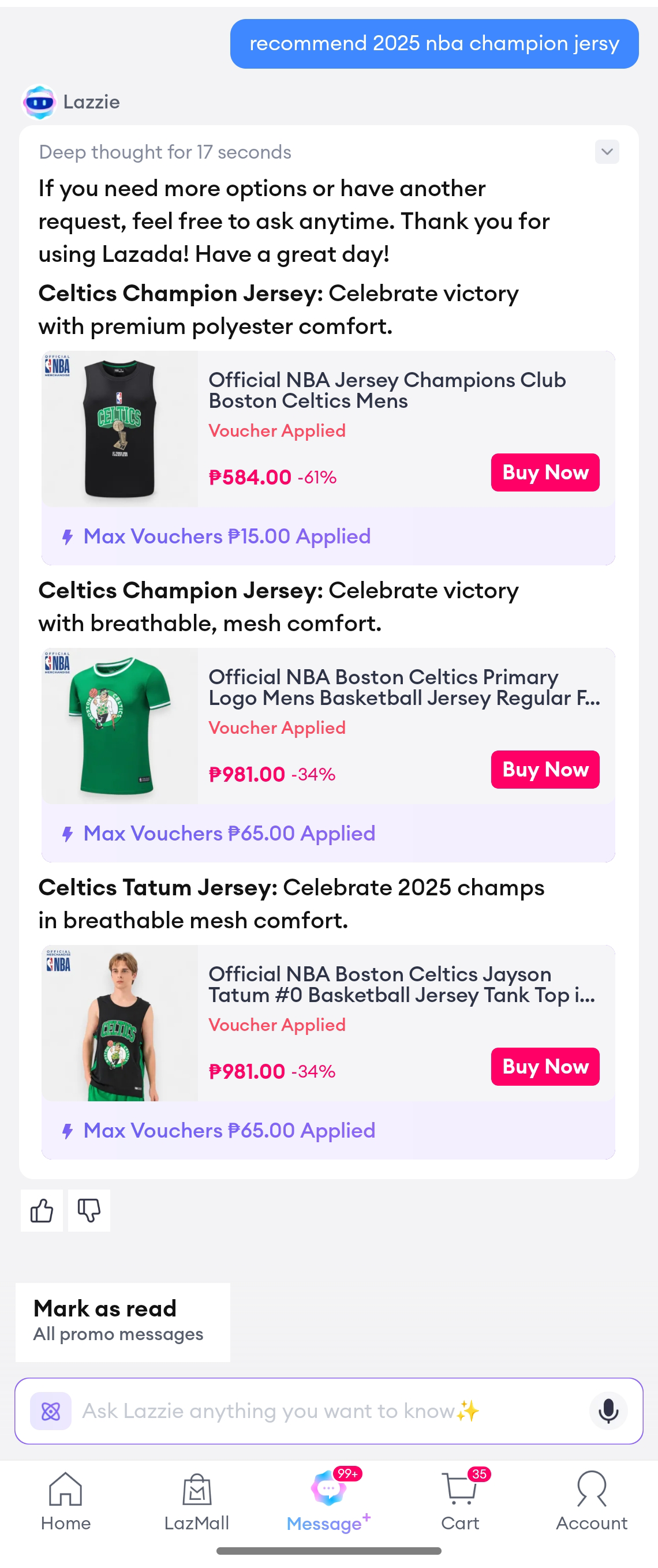 | 准确找到了雷霆队的球衣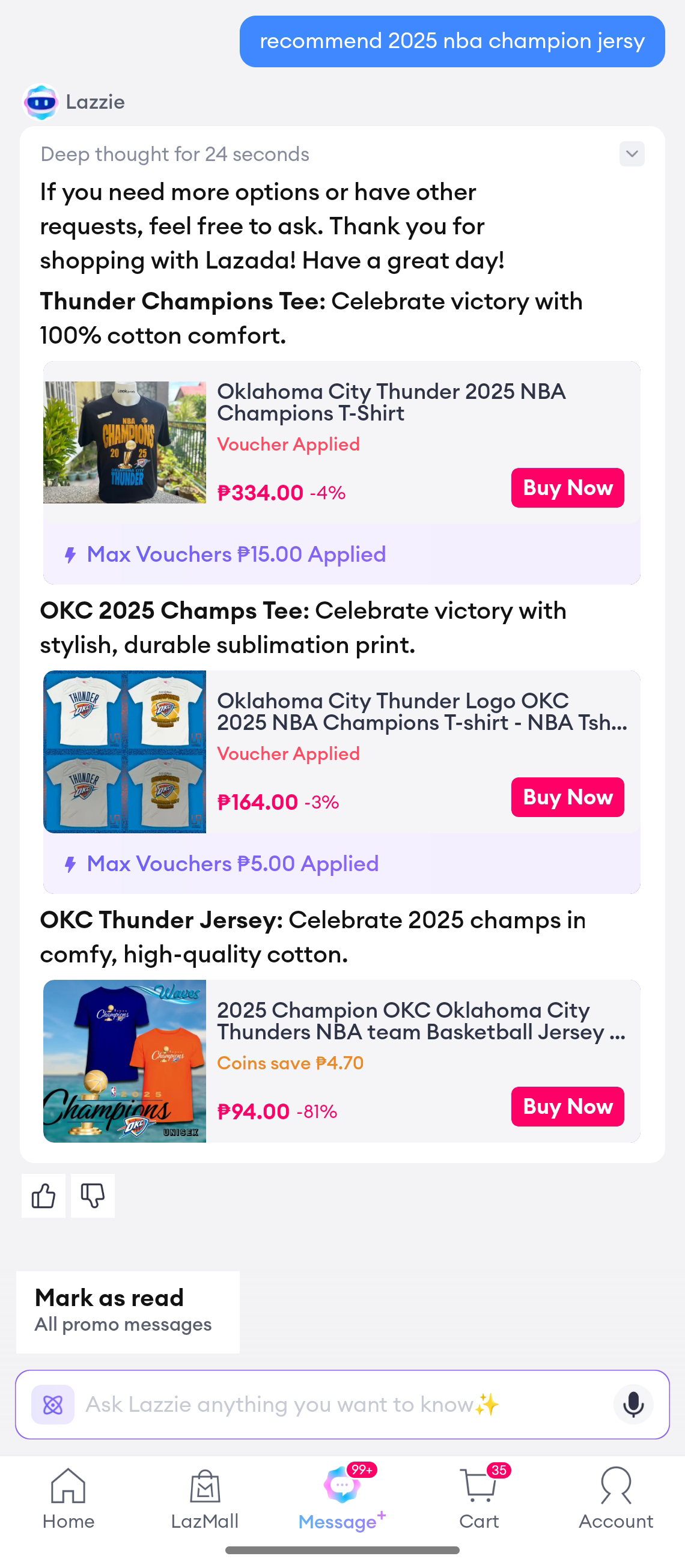 |
| Recommend cat litter and cat scratch boards from one shop(推荐同店的猫砂、猫抓板) | 找到了猫砂和猫抓板,但店铺分别是Irls Online、Hipidog Petwell等。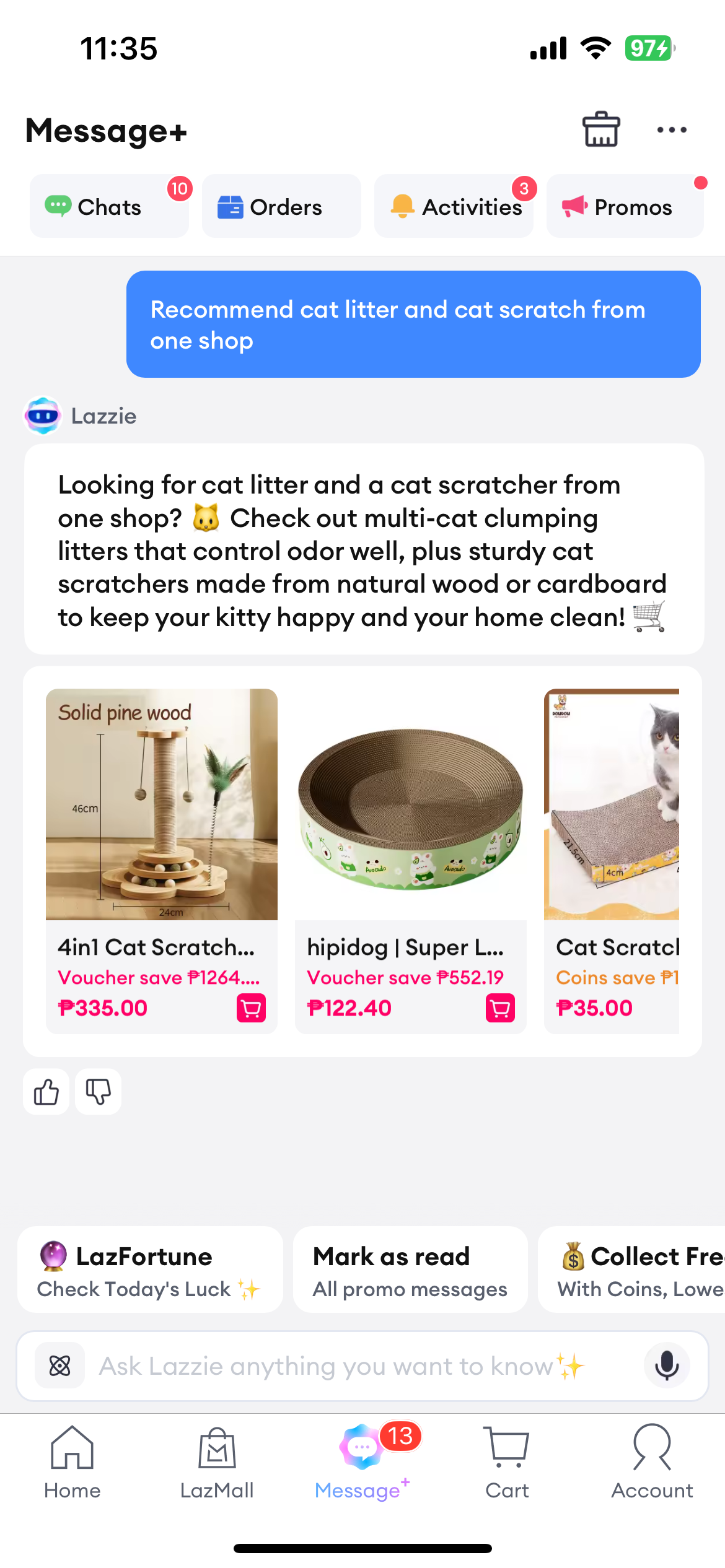 | 找到了猫砂和猫抓板,店铺都是ZIAKA Pet Accessories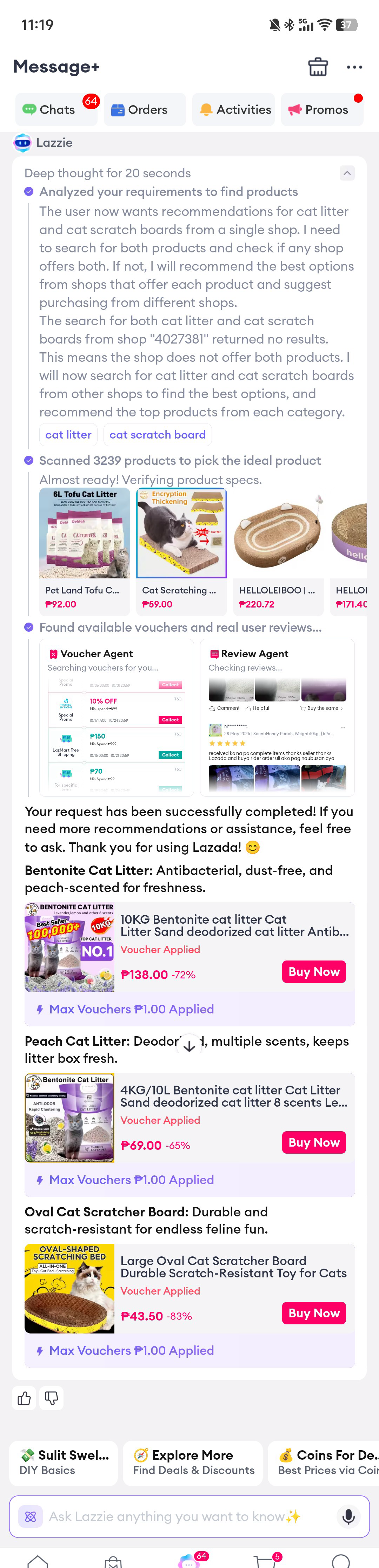 |
5. 总结
我们提出了ShoppingBench —— 一个面向真实电商场景的Agent评估与训练框架,覆盖用券凑单、预算管理、多品同店等复杂用户意图。该框架构建了包含250万真实商品的虚拟购物环境,结合可扩展数据合成、轨迹蒸馏与强化学习,成功将大模型能力迁移到轻量级模型,在多项任务上性能媲美甚至超越GPT-4.1。相关成果已落地于电商对话导购助手,显著提升复杂Query的解决能力。未来我们将进一步探索Agent在不同任务中自适应推理策略,推动电商交互向更智能、高效的方向演进。